
Jest bardzo łatwo zepsuć strukturę drzewa danych w Grasshopper. Zwłaszcza jeśli użytkownik nie wie, co robi. Po prostu chaotyczne modifikuje i upraszcza struktury danych, do czasu przypadkowego osiągnięcia pożądanego rezultatu. To nie jest optymalny sposób pracy. Trzymanie się do prostych zasad, może skutkować mniejszą liczbą problemów ze strukturami drzew w Grasshopperze. Oto moja lista 6 dobrych zasad, jak radzić sobie ze strukturami drzewa danych w Grasshopperze. Zapraszam!

6 zasad pracy ze strukturami drzew w Grasshopperze
1. Używaj panel and param viewer aby sprawdzić strukturę drzewa danych
Ta porada może być dla wielu z Was oczywista.
Oczywiście panel i param vievewr będą pomocne przy sprawdzaniu struktury drzewa danych. Wiele przekształceń lub modyfikacji na liście zwiększa “głębokość” struktury.
Co to znaczy i dlaczego tak jest? Spójrz na przykład poniżej.
Curve Divide: Jako dane wejściowe podajemy pojedyncze pozycje na liście: jedną krzywą i numer podziału.
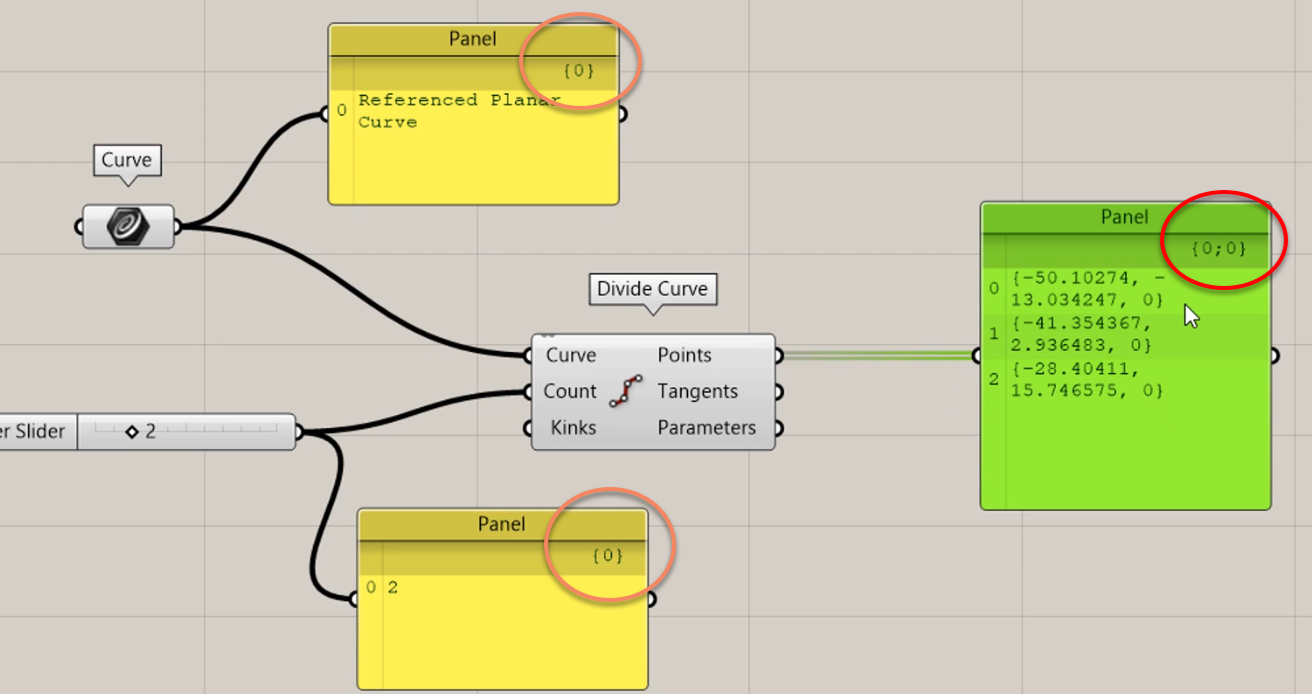
W nawiasie klamrowym na obu listach widać jedno zero (pomarańczowe kółko). Po najechaniu kursorem na wynik składnika Divide Curve, można zobaczyć, że wynik będzie reprezentowany w postaci listy „Points as a list”. Nie każdy komponent zachowuje się w ten sposób. Jednak Divide Curve jest jednym z nich. Oznacza to, że Grasshopper utworzy zupełnie nową listę.
Jeśli spojrzymy na dane wyjściowe (czerwone kółko), zobaczysz dwa zera w nawiasie klamrowym. Początkowe zero reprezentuje oryginalną listę, a drugie zero odpowiada nowo utworzonej ścieżce.
OK.
Można powiedzieć, że ta struktura z wieloma zerami jest po prostu niepotrzebna. Powinno być tam tylko jedno zero. Jednak spójrz, co się stanie, jeśli zmienimy dane wejściowe z jednego elementu na trzy.
Przede wszystkim z wyjścia prowadzi teraz przerywany przewód, co oznacza, że mamy do czynienia ze strukturą drzewa danych.
Po drugie, widzimy, że liczba pozycji z oryginalnej listy przeskoczyła na nową ścieżkę. Zatem pierwszy element odpowiada pierwszej ścieżce, drugi element drugiej ścieżce i tak dalej.
Pamiętaj, że przed nowym numerem ścieżki nadal mamy początkowe zero. Te zera są potrzebne, w przeciwieństwie do tego co myśli wiele osób. Zera sporo mówią o historii struktury drzewa, a bez nich praca ze skomplikowanymi danymi będzie niemożliwa.

Wniosek jest następujący:
Zawsze trzeba śledzić, jak zmienia się struktura w górę sskryptu i być świadomym wszystkich zmian. Niektóre dane wyjściowe komponentu zostaną przedstawione w prostszej formie. Dlatego ważne jest, aby mieć świadomość, że niektóre komponenty tworzą dodatkową scieżkę, a inne nie.
Jeszcze jedna rzecz.
Dzięki Param Viewer możesz wizualizować, jak wygląda struktura drzewa danych.
Możesz go znaleźć w Params–>Util i podłączyć do tego komponentu swoje drzewo danych. Możesz zobaczyć, ile gałęzi i ile elementów znajduje się w Twojej strukturze drzewa danych. Po dwukrotnym kliknięciu pojawi się wizualizacja drzewa danych. Kiedy pracujesz z dużą ilością danych, rozsądniej jest użyć Param Viewer niż panelu, ponieważ w ten sposób uzyskasz przegląd całej struktury danych.
Sign up for free mailing and you will receive Grasshopper TIPS every week.
Join NOW – I’ll send the first secrets of Grasshopper right away!
2. Unikaj simplifications i operacji flatten na strukturach danych
Wiem, że w wielu przypadkach jest to najłatwiejszy sposób wykonania pewnych operacji. Po prostu spłaszcz całe drzewo, a wszystko będzie działać poprawnie. Prawda?
Muszę przyznać, że czasami nadużywam tych operacji, aby jak najszybciej uzyskać i zobaczyć wynik. I wygląda to naturalnie, ponieważ przycinasz „niepotrzebne” zera w swoim drzewie danych. Jednak później łatwo o tym zapomnieć, a to może przysporzyć wielu kłopotów, zwłaszcza jeśli chodzi o łączenie list.
Jak powiedziałem wcześniej, te dodatkowe „0” są niezbędne i mogą zawierać przydatne informacje oraz zapobiegać dodatkowej zmienności na Twojej ścieżce.
Może w prostym skrypcie i tylko w jednym przypadku to wcale nie jest problem. Jeśli dokładnie wiesz, jakie będą twoje dane wejściowe, praca na “płaskich” danych również może być rozwiązaniem. Przypuszczam jednak, że zamierzasz stworzyć klastry lub programy, które mogą rozwiązać wiele przypadków. Nie tylko kilkakrotne powtarzanie części skryptu i robienie tego samego na prostych danych. Grasshopper całkiem dobrze zarządza złożonymi danymi, a dane wejściowe można przedstawić w postaci drzew danych. W takim przypadku należy unikać faltten i simplification oraz systematycznie wykonywać rozgałęzienia drzewa.
Czemu?
Ponieważ kiedy masz zamiar pracować z bardziej zaawansowaną strukturą drzewa danych, te operacje zniszczą cały Twój system bez litości.
3. Używaj shift paths
W porządku, Kris. Ale co, jeśli chciałbym stworzyć skrypt i nie mam pewności, jakie będą dane wejściowe? Co powinienem zrobić zamiast spłaszczać lub upraszczać?
Staraj się jak najczęściej używać Shift Path.
Komponent ten pozwala nam odtworzyć wcześniejsze informacje o strukturze drzewa danych. Używaj tych komponentów, gdy potrzebujesz przejść do poprzedniej struktury danych.
Przesuwanie ścieżek działa jak przesuwanie list; jednak tutaj przesuwamy indeksy we wszystkich ścieżkach drzew danych.
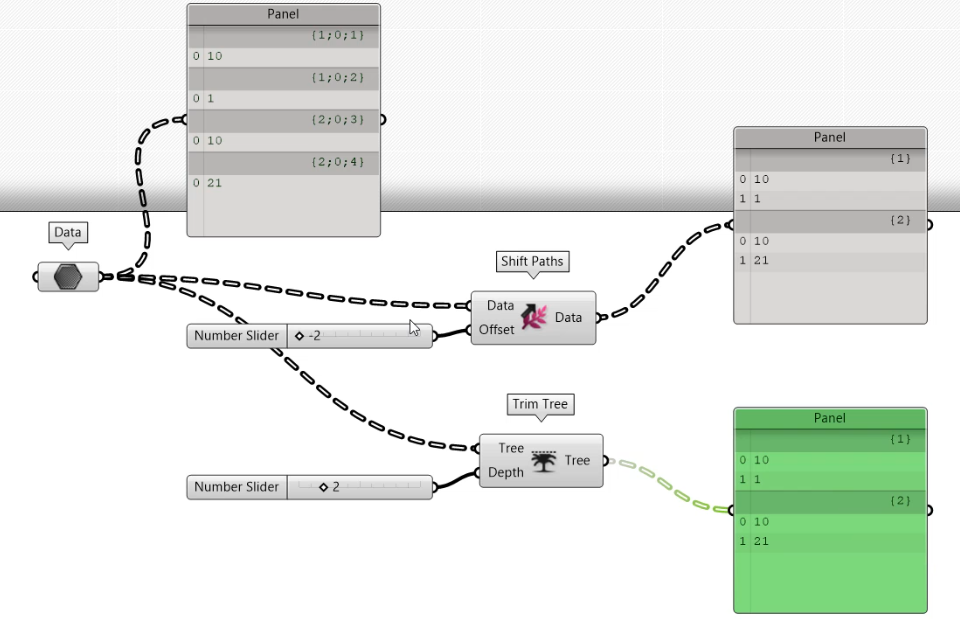
Przesunięcie do zastosowania do każdej gałęzi w postaci liczby całkowitej. Wartość przesunięcia może być dodatnia lub ujemna, a liczby ujemne dają wyniki podobne do komponentu Trim Tree. „Shift Path” o wartość ujemną jest jak „Trim Tree” o wartości dodatniej. Nie rozumiem dlaczego twórcy Grasshoppera stworzyli prawie identyczne komponenty.
Przejdźmy do przykładu:
Liczby dodatnie podchodzą do drzewa danych w inny sposób. Komponent zmienia kolejność drzewa danych na podstawie najmniejszej gałęzi w drzewie. Na przykład: {0;0;0) i {0;3;0) (obie struktury kończą się cyfrą 0) z przesunięciem 2 są łączone w {0}.
Opcja Shift Path wygląda trochę jak kontrolowana opcja Flatten. Pozwala przenieść dane o jedną lub więcej gałęzi niżej lub zwinąć dane w jedną gałąź, podobnie jak opcja Flatten. Jednak teraz umieszczone na jednej gałęzi.
Jeszcze jeden dodatkowy pomocny komponent do pracy ze Strukturami Danych w Grasshopperze.
W oparciu o drzewo przewodnie możesz stworzyć nową strukturę . Jest to przydatne, jeśli chcesz zmienić pewne wartości na podstawie wzorca, który powinien być kontynuowany bez względu na poprzednie zmiany.
Jeżeli więc jeśli musisz wykonać jakieś operacje na ”płaskiej” liście danych, zrób to. Jednak później użyj komponentu Unflatten ze strukturą drzewa prowadzonego.
Innymi słowy, możemy powiedzieć, że Unflatten drzewa danych jest jak przenoszenie elementów z powrotem do oryginalnych gałęzi.
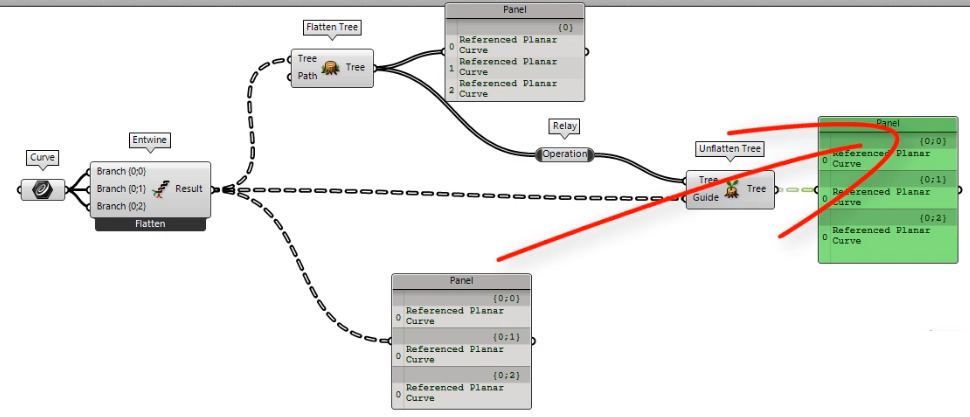
4. Używaj Data tree explode i patch mapper mądrze
W jednym z moich poprzednich artykułów (LINK TUTAJ) zachęciłem do używania Patch mappera. Jednak na końcu artykułu przedstawiłem również wady tego komponentu.
Mianowicie:
Jeśli nastąpi jakakolwiek zmiana w drzewie źródłowym, komponent przestanie działać. Każda operacja uproszczenia, przed komponentem zablokuje ten komponent.
Dlatego musisz być bardzo precyzyjny we wszystkich zmianach i znać strukturę swoich danych.
To samo dzieje się z komponentem Explode Tree. Za każdym razem, gdy zmienia się struktura drzewa, komponent przestaje działać i powoduje wiele problemów.
Dlatego zaleca się zaprojektowanie skryptów tak, aby struktura drzewa nadrzędnego nie miała się zmienić. Użyj komponentu Shift Path, który przedstawiłem w poprzednim punkcie. W takim przypadku uniemożliwisz zmianę danych.
Możesz także zaprogramować kilka reguł w komponencie odwzorowującym ścieżki. Zalecam jednak utrzymywanie porządku, aby korzystanie z tych dwóch komponentów nie stanowiło żadnego problemu.
Czy znasz więcej komponentów, których nie zaleca się używać ze zmienioną strukturą drzewa danych?
Napisz w komentarzach poniżej.

Kolejne wskazówki dotyczące pracy z drzewami danych w Grasshopperze
5. Nie mieszaj drzewa danych
Wszystkie listy, które będą ze sobą ”rozmawiać”, powinny mieć taką samą liczbę pozycji. To jest prosta ogólna zasada, która pomoże ci pracować z Grasshopperem. Jest tylko jeden przypadek, w którym nie ma problemu przy różnych ilościach elementów w liście. Gdy jedna z list składa się tylko z jednej pozycji. Wtedy Grasshopper automatycznie połączy ten jeden element z resztą (na podstawie the longest list matching).
Mimo to polecam przekształcenie tej listy z jednym elementem w listę, która będzie miała taką samą liczbę elementów. Do tej operacji możesz użyć najdłuższego dopasowania listy, aby być świadomym tego, co robisz. Polecam wszystkim początkującym, którzy są nowicjuszami w strukturach danych.
Ta zasada powinna być jednak stosowana również do drzew. Ponownie, najlepiej jest, gdy pracujesz na danych o tej samej strukturze. Tak więc w jednym drzewie danych masz taką samą liczbę gałęzi jak w drugim. Możesz to uzyskać za pomocą operacji na drzewie, takich jak graft, shift tree, path mapper.
Podobnie jak w przypadku list, zasada ta będzie działać również na strukturach, gdy jedno drzewo ma tylko jedną gałąź.
Wniosek jest następujący:
Nie mieszaj liczby gałęzi, ponieważ możesz znaleźć się w miejscu, w którym nie ma możliwości połączenia niektórych list, ponieważ elementy znajdują się w różnych miejscach.
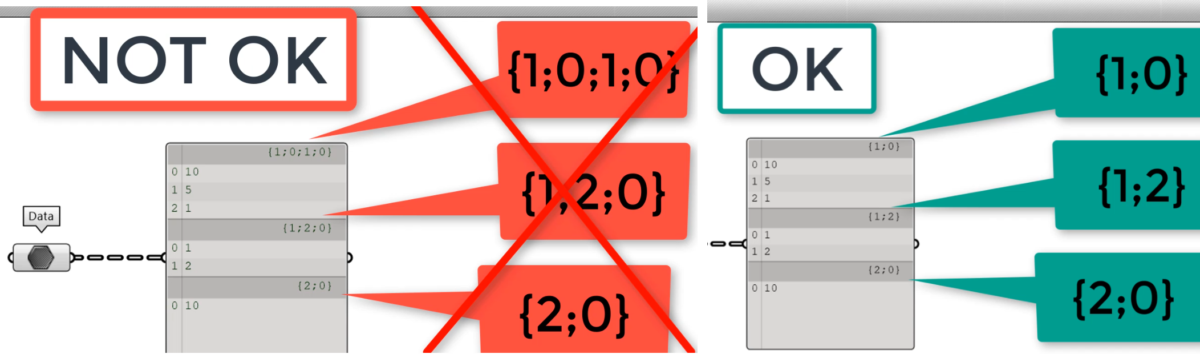
6. Sprawdź, co łączysz.
Znowu ogólna zasada.
Utrzymuj takie same długości ścieżek gałęzi w całej strukturze danych. W każdej gałęzi możesz mieć różną liczbę elementów. I to jest OK i w wielu przypadkach tak będzie. Ale spójrz uważnie na indeks gałęzi. Długości ścieżek odgałęzień powinny być takie same. Jeśli znajdziesz taki z innym numerem, coś poszło nie tak i trzeba natychmiast naprawić. Przede wszystkim z powodu problemu ze scalaniem z innymi listami.
Masz jakieś pytania odnośnie pracy z listami i strukturami drzew?
Napisz do mnie [email protected]
Zawsze odpowiadam !!
Czy masz swoje ulubione triki dotyczące Rhino?
Napisz w komentarzach poniżej, jakich Trików w Rhino używasz podczas pracy z Grasshopperem.
Sprawdź więcej moich porad w Grasshopperze:
5 trików w Grasshopperze na pozbycie się potwora spaghetti
5 trików w Grasshopperze usprawniających współpracę
Jak używać masek w Grasshopperze?
Jeśli chcesz uzyskać więcej informacji o Grasshopper ze i nauczyć się modelowania parametrycznego, pobierz bezpłatny przewodnik – Pobierz bezpłatnie








