
Nasz blog zawiera szereg tekstów o Projektowania na Podstawie Danych oraz używania bazy danych podczas etapu projektowania. I to jest dobry proces. Ale zdałem sobie też sprawę iż wiele projektów jeszcze nie jest gotowa na wprowadzenie tego, ponieważ ich dane są złej jakości, lub też nie ma żadnej praktyki zarządzania nimi!
Postanowiłem zrobić krok w tył i zacząć kształcenie w zakresie danych zupełnie od zera. Dlatego chciałbym tutaj zacząć od podstaw i zająć sie zarządzaniem danych na projektach budowlanych. W niniejszym wpisie zajmę sie podstawowymi definicjami oraz teorią (wraz z praktycznymi przykładami, jak to zwykle robimy), następnie zaś omówię etap tworzenia danych, ich jakość oraz zarządzanie.
Spis treści
Czym są dane?
Zacznijmy od całkowitych podstaw, później zmierzymy się z trudniejszymi zagadnieniami. A więc – co to są dane?
Według definicji z Wikipedii:
Danymi są podedyncze fakty, statystyki lub informacje, często cyfrowe. W ujęciu technicznym, dane to zbiór zmiennych wartości jakościowych lub ilościowych na temat jednej lub więcej osób czy rzeczy.
Dane podają nam informacje na temat rzeczy lub osób, które mogą być przesyłane bądź przetwarzane. Pojedyncza wartość (dana) jest często zwana punktem danych (data point). Dane są właściwie wszystkim co tworzymy na projekcie – od nagrań ze spotkań do skomplikowanych modeli. Kilka przykładów danych na projektach:
- plik pdf (np. Karta Charakterystyki Produktu),
- e-mail wysłany do współpracownika,
- zdjęcie z placu budowy,
- odporność ogniowa ściany w naszym modelu.
Przejdźmy teraz do spraw mniej oczywistych.
Uporządkowane oraz Nieuporządkowane Dane
Dane które tworzymy mogą być uporządkowane lub nieuporządkowane. Zależy od tego jak wyglądają oraz jak je tworzymy. Wspominałem już raz o tym temacie tutaj. Zacznijmy od zdefiniowania różnicy między nimi.
Dane uporządkowane (lub model danych) organizują punkty danych oraz określają relacje pomiędzy nimi. Model danych musi posiadać pewną strukturę zanim zostanie umieszczony w bazie danych.
Obiekty BIM stanowią dobry przykład: model danych przedstawiający ścianę składa się z innych elementów, które definiują ścianę: grubość, długość,odporność ogniowa, materiał, itd. Aby stworzyć ścianę, należy podać dane we wstępnie zdefiniowanym schemacie (każdy punkt danych w odowiednim polu danych). Stąd, uporządkowane dane są również nazywane jako schema-on-write (schemat przy pisaniu). Najważniejszą cechą uporządkowanych danych jest łatwość w wysyłaniu zapytań (query) do bazy danych. Jednakże, stworzenie zestawu danych w bazie danych wymaga trochę wysiłku.
Dane nieuporządkowane to mówiąc wprost – wszystko inne. Nieuporządkowana informacja nie posiada wstępnie zdefiniowanego modelu danych, zatem jest przechowywana w natywnym formacie pliku. Nieuporządkowane dane to e-maile, zdjęcia, dokumenty pdf, notatki ze spotkań, itd. Największa zaleta to prostota ich stworzenia i przechowywania. Jednakże przy wyszukiwaniu, użytkownik musi rozumieć jak dane przetłumaczyć w czystą informacje. Dlatego dane te nazywa się również jako schema-on-read (schemat przy odczytywaniu). Zdjęcie z placu budowy nie posiada swojego modelu danych, dlatego jedynie zorientowany w danym temacie użytkownik jest w stanie przełożyć to na informacje, takie jak liczba pięter, użyty materiał, typ konstrukcji, typ konstrukcji nośnej, itp.
Poniższa tabela pokazuje typy danych z jakimi się spotykamy przy projektach budowlanych:
| Uporządkowane dane | Nieuporządkowane Dane |
|---|---|
| Zestawienia | E-maile |
| Przedmiary | Zdjęcia |
| Obiekty BIM | Nagrania ze spotkań |
| Modele BIM | Notatki ze spotkań |
| Arkusze Excel (zależnie od jakości) | Arkusze Excel (zależnie od jakości) |
| Dokumentacja przetargowa |
Co to są właściwości?
Już wiemy jakie dane które posiadamy na naszym projekcie. Teraz oraz w następnych rozdziałach, skoncentruję się na jednym typie danych: modele BIM i to co mamy w środku. W zasadzie, w BIM mówi się dużo o właściwościach obiektów (properties). A zatem, czym one są? Zdumiwająco, ten aspekt może się stać dość filozoficzny i głęboki, ale ogarnijmy to tak prosto jak się da.
Właściwość to fizyczna bądż abstrakcyjna charakterystyka danego obiektu. Fizyczne właściwości wskazują czym ten obiekt jest w fizycznym świecie: jego kolor, grubość, długość lub materiał z którego jest zrobiony. Abstrakcyjne właściwości to: jego cena, kod danego obiektu (np. wg. Uniclass) lub też kod obszaru kontroli.
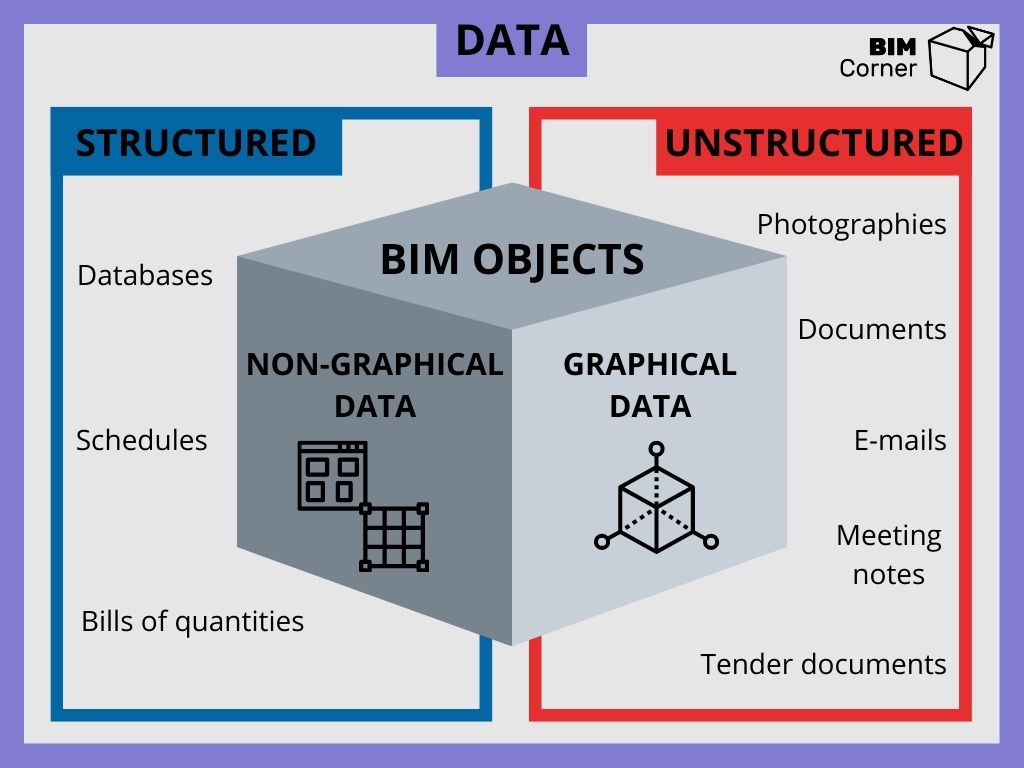
Z jakiego rodzaju właściwościami mamy do czynienia w naszym projekcie? Aby odpowiedzieć na to pytanie, cofnijmy się do naszego pierwszego wpisu na tym blogu. Jak już to tam opisałem, dane BIM dzielimy na graficzne oraz niegraficzne.
Dane Graficzne
Dane graficzne to wszystko co widzimy na ekranie. Należą one do danych nieuporządkowanych, które są głównie używane aby rozróżnić co poszczególne linie bądź powierzchnie oznaczają. Oto typy danych graficznych:
- grubość linii
- typ linii (ciągła,
- przerywana, kropkowana)
- kolor
- adnotacja
- warstwa
- kształt modelu
- znaki i symbole
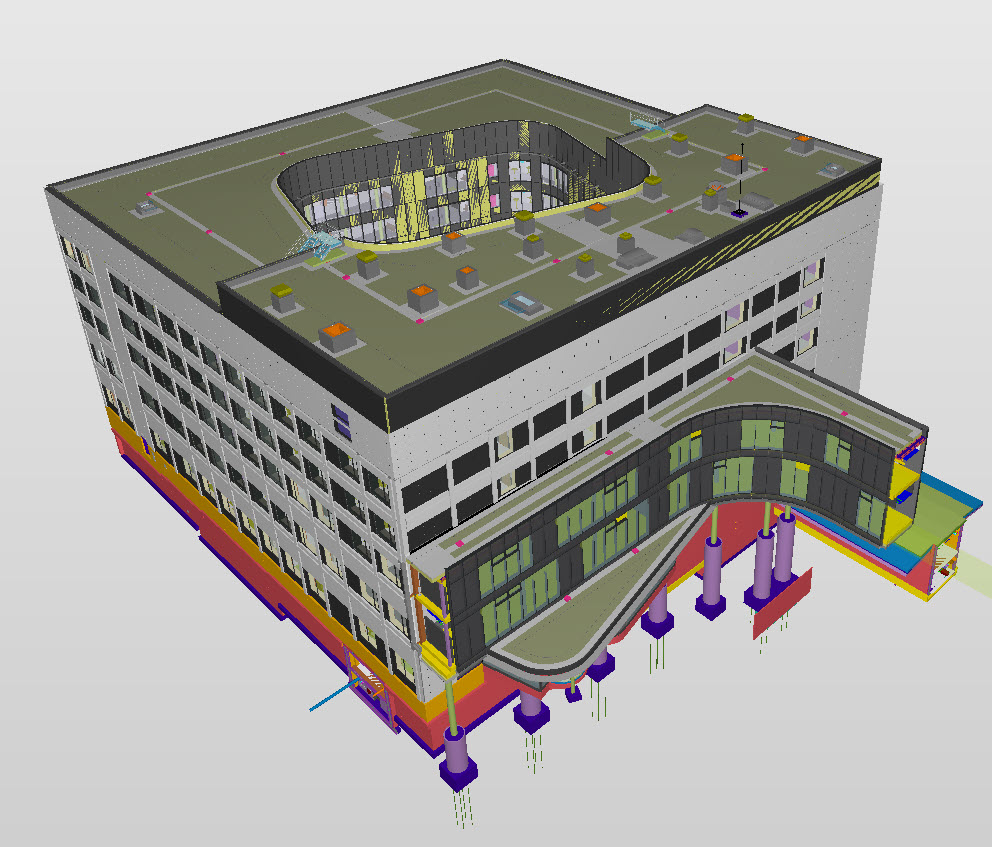
Dane niegraficzne
Są to wszystkie informacje znajdujące się w szkicach bądź modelach. Mogą to być różne zestawienia ilościowe, powierzchnia pomieszczenia lub objętość. Są to wszystkie właściwości, które bezpośrednio pochodzą z graficznego projektu. Jeżeli bierzemy projekt 3D za pustą kombinację powierzchni, jego właściwości opisują dokładnie to.
Modele BIM zawierają więcej różnorodnych danych. Oddzielenia elementów budynku od kształtu 3D oraz podzieleniu je na odpowiednie klasy/kategorie spowodowało, że możemy nadawać różne właściwości różnym elementom. Każda kategoria zawiera liczne właściwości, zarówno te fizyczne, jak i abstrakcyjne.
Właściwości zdefiniowane przez użytkownika
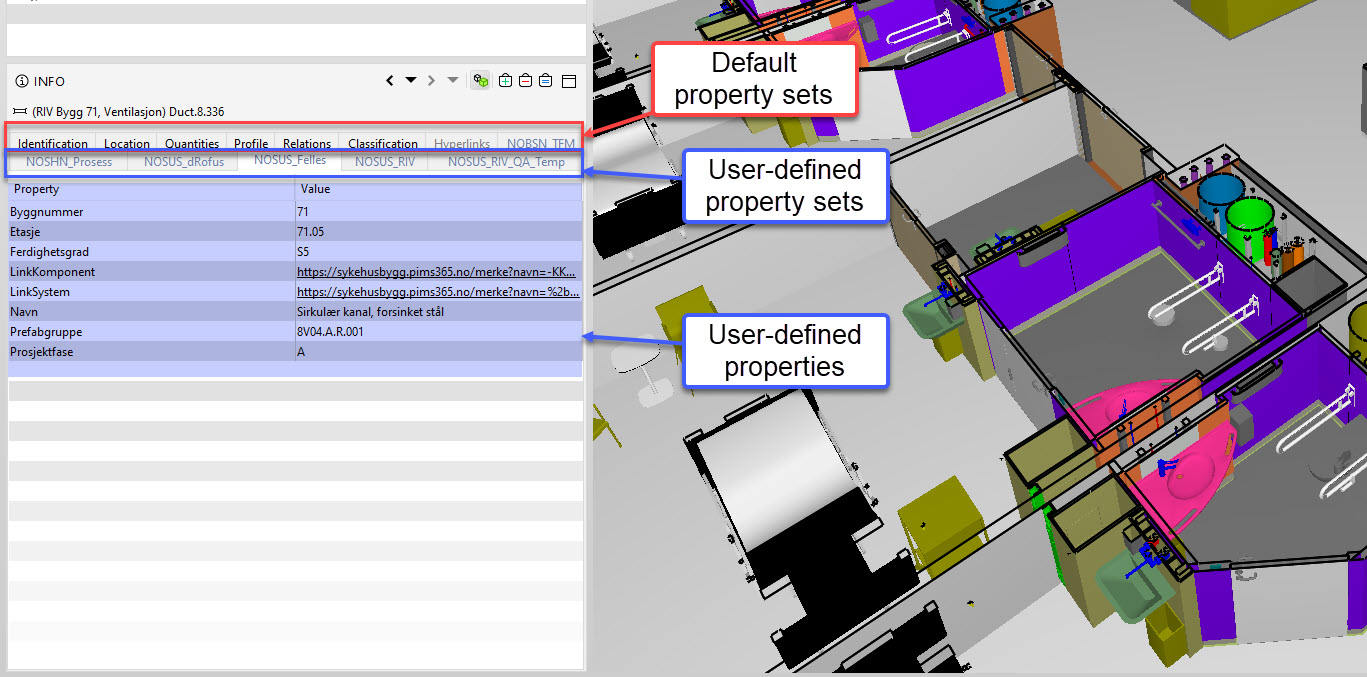
Zbiory właściwości
Każdy obiekt BIM posiada setki właściwości. Gdyby wypisać je jedna po drugiej to bałagan mamy gwarantowany. Dlatego też wprowadzamy zbiory właściwości (property sets) – grupowanie danych w obiektach. Schemat IFC posiada swoje własne grupowanie, tak i każde narzędzie BIM posiada swoje własne. Można je rozumieć tak jak rozdzialy w książce czy arkusze w Excelu.
Predefiniowane zbiory właściwości są logicznie pogrupowane. W przeglądarce IFC zazwyczaj widzimy: Identyfikacja, Lokalizacja, Relacje oraz Ilości.
Zbiory własciwości stworzone przez użytkownika grupują razem dodatkowe właściwości.Takie grupowanie jest opisane w BEP (BIM Execution Plan) i zalecam stworzenie i przestrzeganie zasad ich grupowania. W przeciwnym razie, użytkownik może błędnie je przyporządkować lub nazwać (też to przerabiałem).
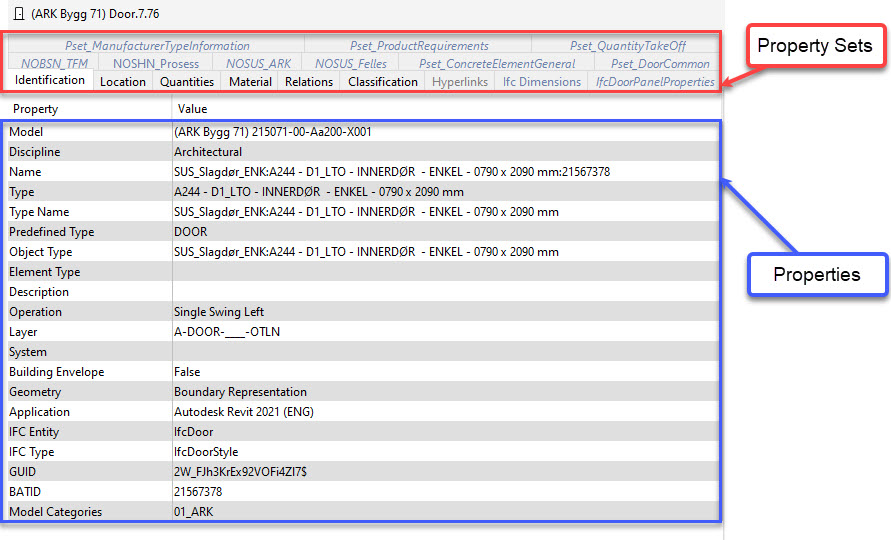
Czym jest model BIM?
Po co potrzebne nam są właściwości?
Aby posiadać wszystkie dostępne informacje w jednym miejscu.
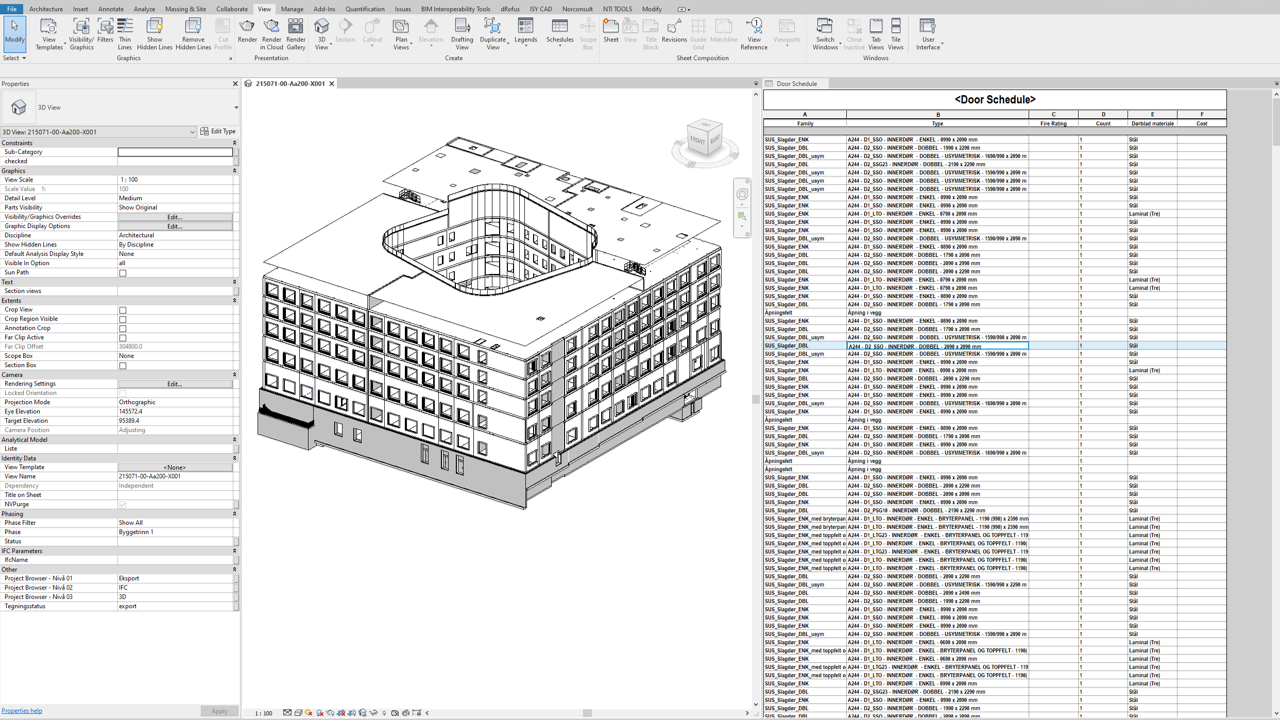
Tworzenie zestawień oraz przedmiarowanie.
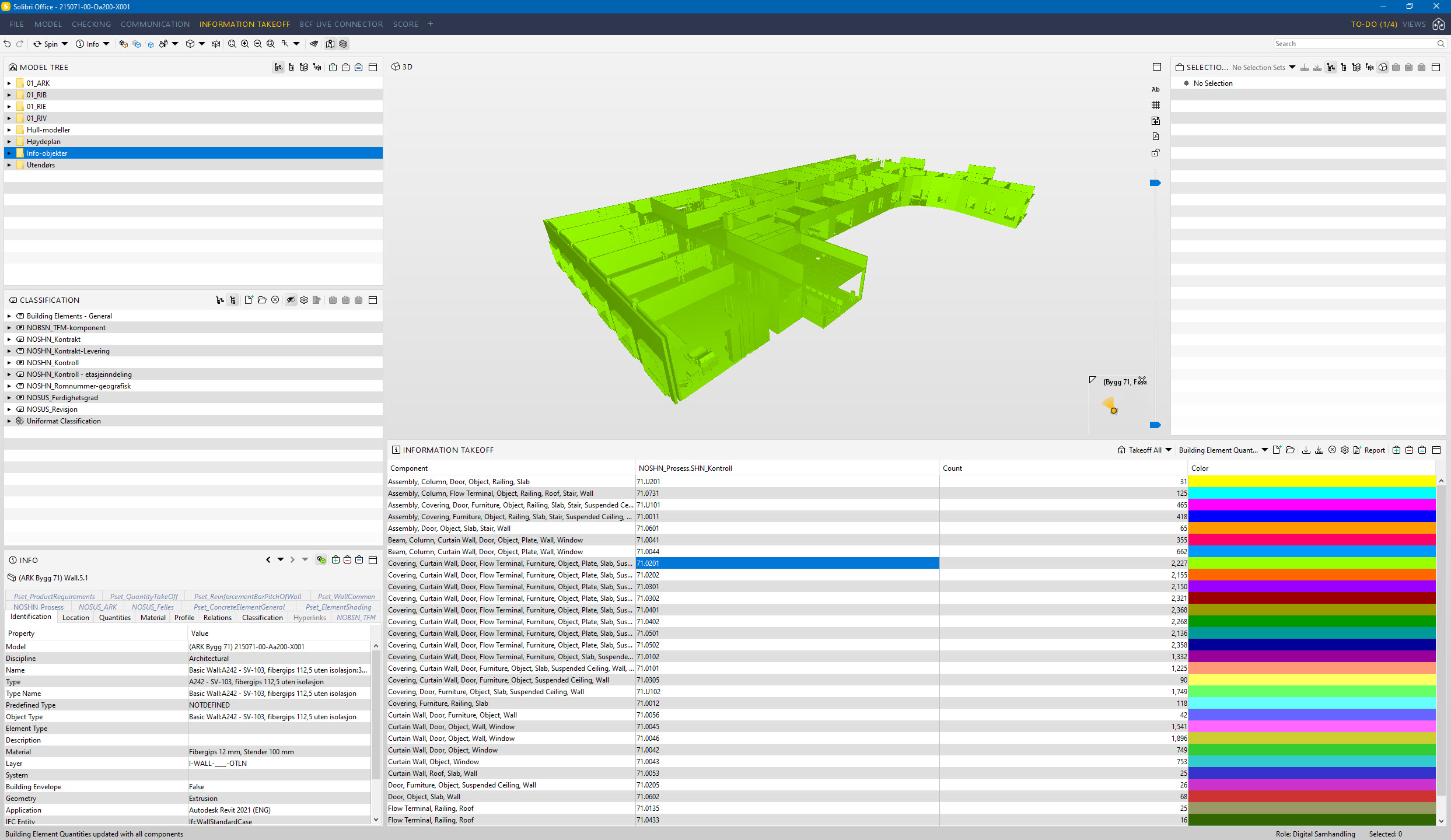
Filtrowanie.
To jest prawdziwa potęga właściwości obiektów i modelowania BIM. W rozdziale 2 stwierdziłem, że największą korzyścią uporządkowanych danych jest prostota w wyszukiwaniu danych oraz filtrowanie.Modele BIM umożliwiają szybkie filtrowanie oraz sortowanie otrzymanych informacji. Zapytania takie jak “Pokaż wszystkie obiekty za które odpowiadam przy projektowaniu. Pokaż wszystkie obiekty które są jeszcze na wczesnym etapie projektowania.” mogą być bardzo sprawnie zaaplikowane.
Eksportowanie danych do oprogramowania typu Business Intelligence
Jako że BIM jest bazą danych, a właściwości kolumnami w tej bazie, oznacza to, że łatwo możemy ponownie użyć nasz projekt w różnych innych oprogramowaniach. Nic nie zmusza nas do współpracy tylko przez pryzmat naszego modelu graficznego. Równie dobrze możemy skoncentrować się jedynie na danych i wysłać naszą bazę danych BIM do oprogramowania takie jak Power BI (jeżeli chciałbyś nauczyć się jak to zrobić, daj znać w komentarzu, stworzę odpowiedni wpis). To z kolei otwiera nowe możliwości do analizy danych w naszych projektach.








