
Spis treści
Jakie kroki należy podjąć w procesie czyszczenia danych?
Proces uzyskania danych o wysokiej jakości może zostać osiągnięty przez iterację tych czterech kroków:
- Inspekcja
- Czyszczenie
- Weryfikacja
- Raportowanie
Na pierwszy rzut oka wydaje sie to nudne i żmudne, ale jak zobaczycie, może to być całkiem proste. Wszystko zależy jak duży zbiór danych posiadamy oraz jak chaotyczne dane otrzymujemy. Zazwyczaj AEC operuje na ograniczonych danych (choć ich wielkość systematycznie wzrasta), ale o nienajlepszej jakości.
Inspekcja
Najpierw, spójrz na dane. Twój cel to odkrycie nieoczekiwanych, nieprawidłowych, oraz niespójnych danych. Zapamiętaj lub zapisz nieprawidłowe schematy – zajmiemy się nimi w następnym kroku.
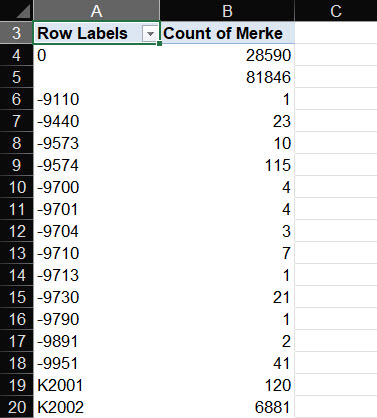
Dobrym pomysłem jest stworzenie podsumowującej statystyki (np. tabelę przestawną) i sprawdzanie czy są literówki lub powtarzające się błędy w kolumnach. Jeżeli masz przeprowadzić analizę statystyczną danych (co jest raczej rzadkie w naszej branży), przydatne jest stworzenie wizualizacji – bardzo pomagają w identyfikacji wartości odstających czy tez nieoczekiwanych.
Czyszczenie
Usuwanie duplikatów
Usuwanie duplikatów często stanowi pierwszą czynność przy czyszczeniu danych. Jak również jest najbardziej kompleksowe. Jest to szczególnie istotne przy łączeniu kilku źródeł danych. Na przykład podczas federowania modeli lub tworzenia wykazu typu elementów z wielu tabel dostarczonych przez różne branże.
Aby usunąć duplikaty, musisz najpierw znaleźć wartość, która musi być unikalna. Może to być numer elementu, numer pomieszczenia lub ID. Czasem, wystarczy, że unikalny jest zestaw kolumn (np. dane klienta – imię, nazwisko oraz adres mogą posiadać duplikaty w jednej kolumnie, natomiast razem tworzą unikalny zbiór danych).
Najłatwiejszą operacją jest umieszczenie danych w Excelu i uzycie funkcji “usuń duplikaty”. Ty decydujesz które kolumny należy traktować jako unikalne, natomiast Excel pozbywa się powtórzeń. Należy tutaj jednak być ostroznym, gdyż nie masz kontroli nad tym, jakie wiersze są usuwane. Aby zaznaczyć duplikaty przed ich usunięciem, możesz użyć narzędzia “formatowanie warunkowe”.
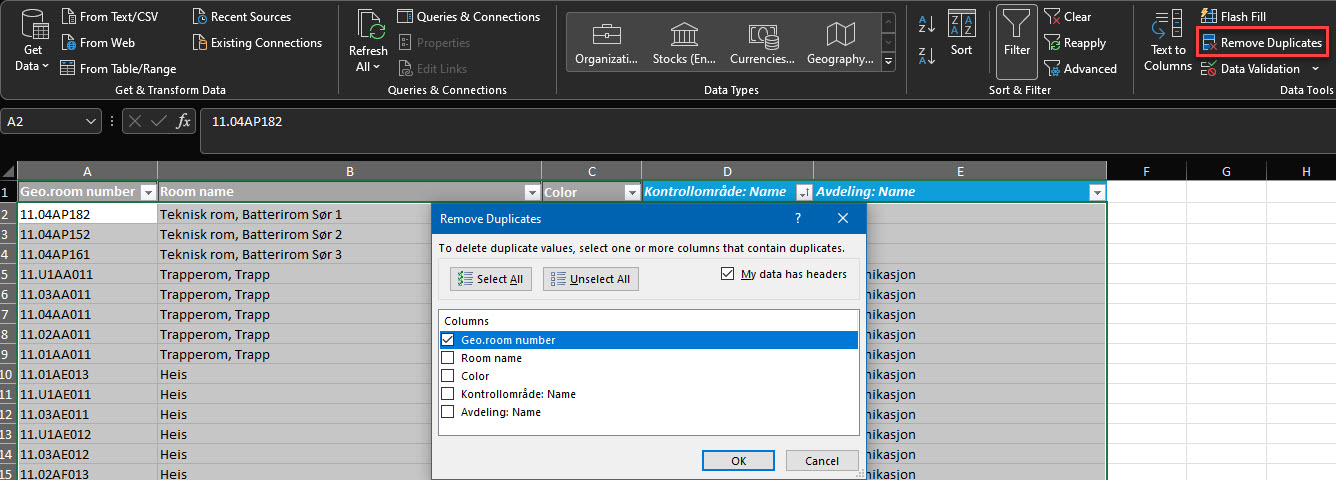
Usuwanie wartości odstających oraz nieznaczących danych
Dane nieznaczące to te, kiedy informacje w tabeli nie pasują do Twojej analizy. Przykładowo wyeksportowane wszystkie obiekty w kategorii “ściany”, podczas gdy Ty potrzebujesz tylko ściany wewnętrzne. Mniej danych czyni analiza łatwiejszą, zaś w niektórych przypadkach – tylko taka będzie prawidłowa (w przypadku kiedy sumujesz powierzchnię ścian dla ścian wewnętrznych).
Ustawienie prawidłowych filtrów na kolumnach załatwi nam sprawę z nieznaczącymi danymi. Czasami konieczne jest użycie dodatkowej kolumny, aby przefiltrować nieznaczące dane. Przykład: zarówno ściany zewnętrzne jak i wewnętrzne posiadają przypadkową nazwę typu i niełatwo jest je odróżnić poprzez ten parametr. Wiesz natomiast, że zewnętrzne ściany posiadają cegły jako materiał warstwy zewnętrznej. Dodając tę kolumnę do zestawienia ułatwi nam to wyfiltrowanie nieznaczących danych.
Z drugiej strony, wartości odstające to są dane leżące daleko od większości uzyskanych rezultatów. Dla nas, w przemysle budowlanym, często oznacza to błędy. Jako przykłady użyjmy ceny jednego typu okna. Załóżmy, że większość cen waha się w zakresie 300€ – 500€, ale jeden typ kosztuje 2000€. Musimy sprawdzić, czy tak faktycznie jest to wartość prawdziwa, czy pomyłka.
Wartości odstające mogą być identyfikowane poprzez narzędzie formatowania warunkowego w Excelu. Wybierz graniczny próg od którego dane odstają, i wtedy zostaną one zaznaczone przez program. Od Ciebie będzie zależeć co z nimi zrobisz.

Naprawienie błędów strukturalnych
Strukturalne błędy w zbiorze danych to literówki, różne konwencje nazewnictwa, nieprawidłowe użycie dużych liter, błędy składni, oraz nieprawidłowe wpisy numeryczne.
Podczas pracy z prostszymi zbiorami danych, najłatwiej dla mnie jest stworzenie tymczasowej tabeli przestawnej aby dowiedzieć się gdzie błędy strukturalne występują (taka sama metoda jak podczas inspekcji). Posiadanie takiej listy ułatwia poprawianie błędów aż do momentu gdy tabela jest czysta.
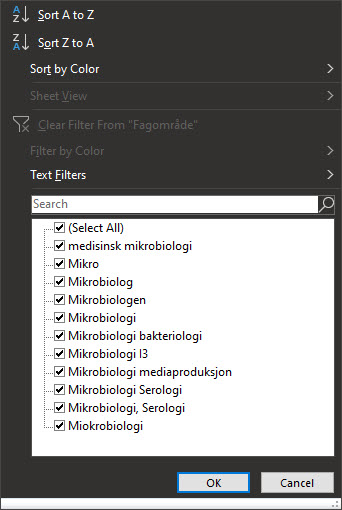
Aby naprawić błędy strukturalne zazwyczaj przeprowadzamy następujące czynności:
- Znalezienie i zastąpienie niewłaściwego tekstu
- Zmiana wielkości liter
- Usunięcie zbędnych spacji oraz znaków niedrukowalnych
Niespójne dane
Różne źródła mogą posiadać różne konwencje w przedstawieniu danych, co może spowodować niejasności i nieporozumienia w zbiorze danych – możemy mieć wątpliwości czy przedstawione wartości należą do tej samej kategorii czy też nie. Zdefiniuj jaki format/składnia jest obowiązująca, a następnie popraw pozostałe wartości.
Podejmowane czynności są podobne do tych, gdy poprawia się błędy strukturalne: zamiana tekstu, usunięcie zbędnych znaków, itp.
Poniżej w tabeli przykład niespójności w różnych modelach. Mając takie niespójności, możemy na przykład błędnie obliczyć ilość wyposażenia wymaganą w każdym pomieszczeniu.
| Źródło | Dane zgodne | Dane niezgodne |
|---|---|---|
| Baza Danych pokoju | AA.1023 | AA.1023 |
| Model Arch. | AA.1023 | AA 1023 |
| Model instalacji | AA.1023 | 1023 |
| Baza danych FM | AA.1023 | AA.1023 |
Postępowanie z brakującymi danymi
Brakujące dane (puste pole lub wartości “null”, które powinny zawierać dane) może spowodować problemy podczas przeprowadzania analizy danych, a zwłaszcza podczas wykonywania matematycznych operacji przeprowadzanych na nieistniejących danych.
Co powinniśmy zrobić z brakującymi danymi, w dużej mierze zależy od tego, do czego potrzebujemy tych danych oraz ile jest pustych pól danych. Możesz wykonać każdą z poniższych operacji:
Usunięcie
Jeżeli brak danych zdarza się rzadko lub wartość nie jest konieczna do przeprowadzenia analizy, wtedy można usunąć całe rzędy zawierające takie dane. Jeżeli w jednej kolumnie brakuje dużo wartości, możesz usunąć całą kolumnę.
Może to być przypadek kosztorysowania dużych sum. Jeżeli widzisz brakujące dane dotyczące tańszych elementów, które znacząco nie wpływają na wycenę, lepszym rozwiązaniem może być usunięcie tych rzędów danych zamiast próba naprawiania ich. Ale pamiętaj – tracisz wtedy informacje.
Oszacowanie
Jeżeli brakujące dane tworzą jakiś wzorzec lub są one niezbędne, oszacowanie brakujących wartości może być dobrym rozwiązaniem. Oznacza to przypisanie brakujących wartości w oparciu o inne obserwacje.
Dobrym przykładem może byc cena elementu do obmiaru. Jeżeli spośród 20 typów okien, brakuje ceny dla 1 typu, wtedy można przypisać im jakąś cenę w porównaniu do cen pozostałych typów oraz innych wartości parametrów (rozmiar, materiał, klasa dźwiękoszczelnośći, itp.).
Oflagowanie
Jeżeli znajdziesz jakiś wzorzec odnośnie brakujących danych lub jeżeli przypuszczasz że brakujące informacje jest informacją samą w sobie, powinieneś rozważyć ich oflagowanie. Jes to potraktowanie brakujących wartości jako wartość. Brzmi paradoksalnie? Weźmy przykład zestawienia drzwi z kolumną o etykiecie “Odporność Ogniowa”. Co oznacza fakt, że jedna trzecia z wierszy nie ma żadnej wartości w tej kolumni? W rzeczywistości, to nie jest błąd a fakt, że te drzwi nie mają żadnej klasy odporności na ogień. W takim przypadku, nie jest to wartość null, tylko kategoria informacyjna “Brak”. Powinienes stworzyć taką flagę i przypisać ją wszystkim brakującym wartościom w danej kolumnie.
Przykład brakujących danych w tabeli. Możemy oszacować wartości „wymiar” z nazwy typów oraz możemy oflagować brakujące wartości „Odporność Ogniowa”.
| ID | Nazwa | Wymiary | Odporność ogniowa |
|---|---|---|---|
| ... | ... | ... | ... |
| DW-86 | Podwójne drewniane drzwi wewnętrzne 1990x2090 | 1990x2090 | |
| DW-87 | Pojedyncze drewniane drzwi wewnętrzne 990x2090 | 900x2100 | |
| DW-88 | Podwójne stalowe drzwi wewnętrzne 1990x2290 | EI30 | |
| DZ-89 | Pojedyncze aluminiowe drzwi zewnętrzne z panelem bocznym 1390x2090 | EI30 | |
| ... | ... | ... | ... |
Ta tabela pokazuje przykład, co można zrobić z brakującymi danymi podczas przygotowywania do analizy zestawienia drzwi (usunięcie wiersza „Drzwi zewnętrzne”, oszacowane wartości w kolumnie „Wymiary” i oflagowanie brakujących wartości „Oporność ogniowa” jako „Brak”).
| ID | Nazwa | Wymiary | Odporność ogniowa |
|---|---|---|---|
| ... | ... | ... | ... |
| DW-86 | Podwójne drewniane drzwi wewnętrzne 1990x2090 | 1990x2090 | Brak |
| DW-87 | Pojedyncze drewniane drzwi wewnętrzne 990x2090 | 900x2100 | Brak |
| DW-88 | Podwójne stalowe drzwi wewnętrzne 1990x2290 | 1990x2290 | EI30 |
| ... | ... | ... | ... |
Weryfikacja
Raportowanie
Dobrym zwyczajem jest rejestrowanie zmian które dokonałeś na surowym zbiorze danych. Może odkryjesz systematyczny powód dlaczego dane są niewłaściwie wprowadzane. Może będzie możliwe użycie tego raportu celem ulepszenia metody tworzenia danych?
Pożyteczną rzeczą jest też dołączenie takiego raportu, jeżeli przesyłasz dane komuś innemu do analizy. Zwłaszcza jeżeli nie posiadasz wystarczającej znajomości danego obszaru. Może część danych którą poprawiłeś okaże się na końcu nieprawidłowa? Albo być może pominąłeś dane, które faktycznie są bardzo istotne? Znawca domeny będzie wiedział od razu przy pierwszym rzucie oka.








