One of the most challenging aspects of Grasshopper is understanding data tree structures, which can be a daunting task for even the most experienced users. However, with practice and the right guidance, mastering data trees can unlock a whole new level of design possibilities. In this article, I will explore the fundamentals of data trees in Grasshopper and provide exercises to help you practice and better understand this concept. With the help of this article and the attached exercises, you will have a solid understanding of how data trees work and be able to apply this knowledge.
Table of Contents
1. Why do we need data trees in Grasshopper?
Well, data trees are particularly useful when working with complex models that require data to be arranged in a specific way. Usually used to store and organize large amounts of data. This structure allows us to store data in a hierarchical manner, with multiple lists within one list. For example, if you are designing a building facade and need to organize the placement of various panels, data trees can help. You can create lists of panels for each section or the floor of the facade, and then group these lists together using a data tree structure. This allows you to easily manipulate the panels within each section and across the entire facade. Instead of making changes for each floor separately, you can make the change on all floors at once.
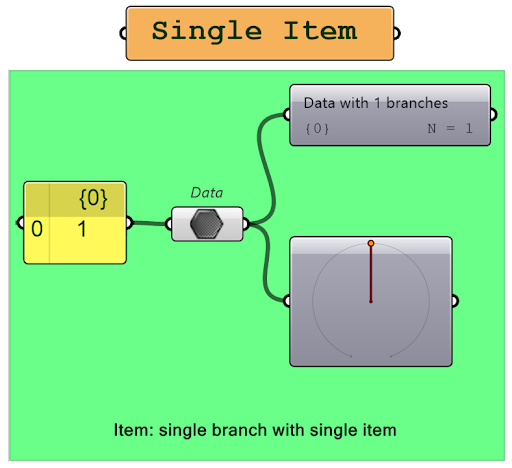
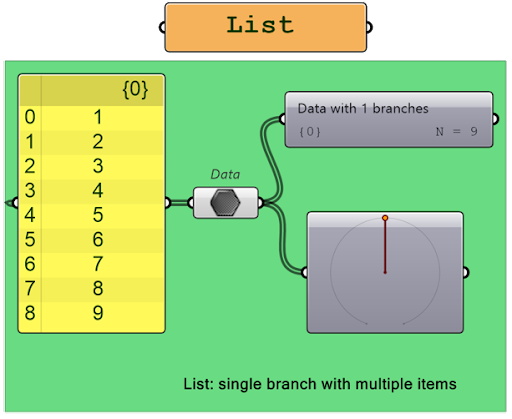
2. Single-item lists and lists
To understand data tree structures, let’s first discuss single-item lists and lists. A single-item list contains a single element.
While a list contains multiple elements. Lists can be thought of as a series of boxes or containers, each containing a single data item, which can be accessed and manipulated individually or as a group.
You can easily differentiate between the two by observing the difference in the lines that represent them; a single-item list is represented by a single line, while a list is represented by a double line.
3. Data trees structure in Grasshopper
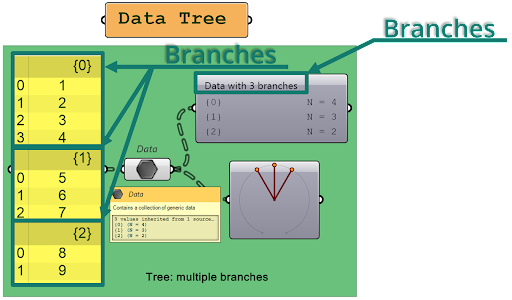
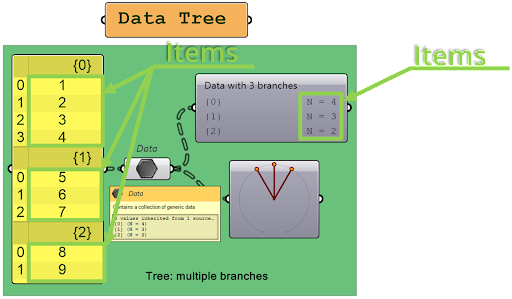
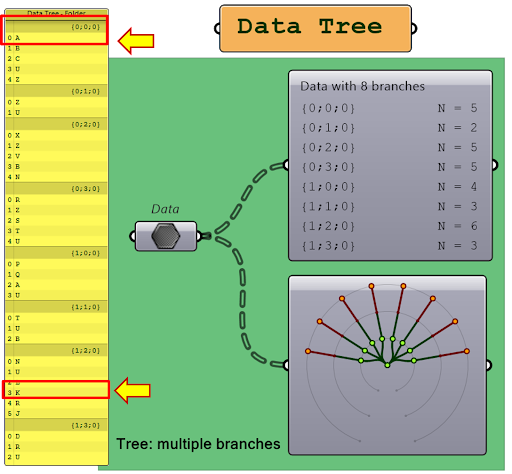
Data tree structures take things to the next level by introducing multiple branches. Each branch is like a separate list within the data tree, and these branches are represented by curly brackets with a name and a number inside. You can use the param viewer (component in Grasshopper) to see how many branches are in the data tree and how many elements are in each branch. Pay attention to the wire appearance while sending data trees. Wires will be thick dashed lines.
There is new terminology connected to the data trees. Let’s take close look at them.
One of the most important concepts in data trees is branches. Think of a branch as a container that holds a collection of items. One branch, one separate list. Each branch can have multiple sub-branches, creating a hierarchical structure. Within each branch, items are stored in a specific order, starting from the left and going towards the right.
Z komponentem Parameter View możesz sprawdzić liczbę gałęzi w swoim drzewie danych.
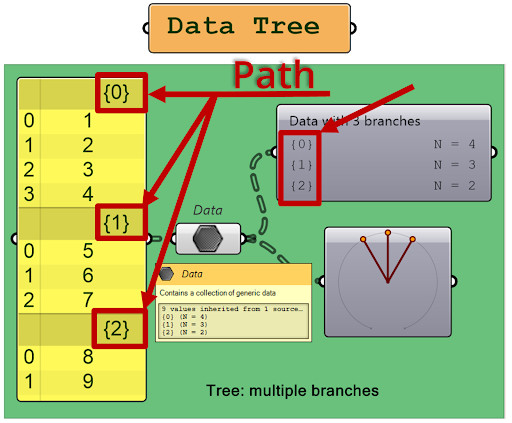
5. Paths
Paths are used to locate and access items within the tree. They consist of a list of indices, separated by semicolons, that describe the location of the item in the tree. For example, the path {0;2;1} refers to the third item in the second sub-branch of the first branch.
Ścieżki w Grasshopperze umieszcza się w nawiasach klamrowych. W bardziej zaawansowanych drzewach ścieżki są oddzielane średnikami, na przykład {0;1;0} {0;1;1} {0;2;0} {0;2;1}.
6. Items
Each branch can contain multiple items, and you can operate on these items just like you would with a list.
W każdej gałęzi drzewa danych może być różna liczba elementów
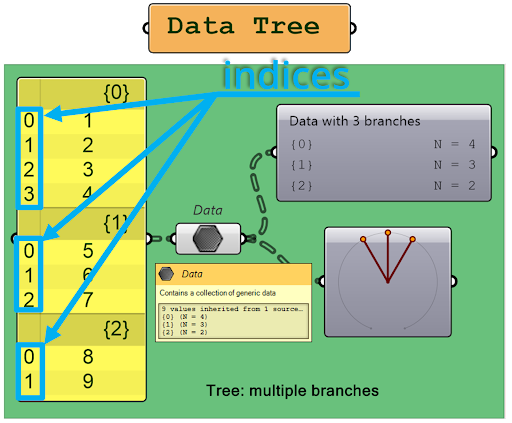
7. Indices
Indices determine the position of an item within a branch. Each item in a branch is assigned a unique index number, starting from 0 and increasing by 1 for each subsequent item. These index numbers are used to access and manipulate the items within the branch.
W każdej gałęzi (liście) indeksy zawsze zaczynają się od 0.
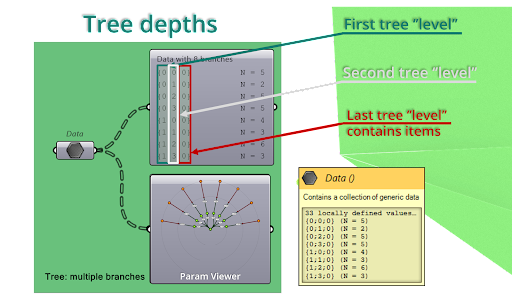
As the complexity of the data tree grows, you can give more branches to store more data. The number of branches is referred to as the tree depth, which is described in curly brackets with a semicolon. The first number before the semicolon indicates the first tree level, and subsequent numbers indicate the subsequent tree levels. The last level always contains items, and you can identify them with the “N=” followed by the number of items.
For example, a data tree with a depth of 2 would have one main branch with multiple sub-branches. Each sub-branch can then have its own set of sub-branches, creating a hierarchy.
Przedstawiający drzewo danych z kilkoma poziomami gałęzi i elementami
8. Important topics to remember with data trees in Grasshopper
Order of branches and items is always from left to right
This means that the first branch is on the left, and the last branch is on the right, and the items within each branch are also ordered from left to right.
GH stores data with a hierarchy
This hierarchical organization allows for the manipulation allowing for the organization of large amounts of information in a structured manner.
Trees grow incrementally and linearly
This means that as new branches are added, they are placed in a linear sequence, creating a clear and logical structure that can be easily navigated.
Structure can be changed at any time
This allows for the optimization and customization of data organization to better suit specific needs and analysis goals.
9. Bad data trees structure
It’s important to understand that the structure of a data tree can be changed at any time. Operations such as adding or removing branches, or moving to different levels can be carried out. However, this does not change the items within the structure, and they remain the same.
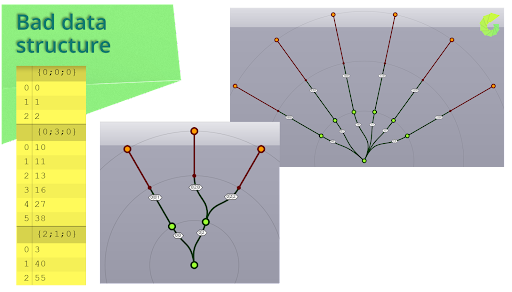
Unfortunately, some data tree structures can be really bad examples. When we look at the example on the screen, we see that the tree is not growing linearly. The curly brackets in the param viewer on the left show that there is missing data for path {0;0;0}. The next one goes to {0;3;0} and third to {2;1;0}. This is a bad example of a data tree structure.
Przykłady złej struktury drzewa danych
It’s crucial to remember that working on an irregular data tree structure can lead to problems. Therefore, it is wise to avoid such structures as a principle. Instead, we should strive to create a good data tree structure. By doing so, we ensure that our data is organized, accessible, and easy to work with. A well-structured data tree will not only help us save time but also improve the efficiency of our work.
10. Data trees as a folder structure
The Data tree structure in Grasshopper can be compared to the folder structure system in Windows. Each folder corresponds to a particular data tree, and the last folder in the last branch is the place where an item is stored. In the case of the data tree, the item is a notepad document with data stored in it.
Drzewo danych przedstawione w postaci hierarchii folderów w systemie Windows
For example, the first item in the data tree {0;0;0}[0] can be represented by a notepad file that includes the letter A, while {1;2;0}[3] would be a notepad file that includes the letter K. This hierarchical system allows for easy organization and storage of data, similar to how the folder structure system organizes files and documents on a computer.
Konkretne elementy znajdujące się w systemie folderów
11. Summary of Data trees in Grasshopper
In this article, I explained the complex concept of data trees and how they are used to solve complex geometry problems. It is recommended to watch the accompanying video on data tree generation in Grasshopper, where the manual process of creating trees is demonstrated. The article also covers the four different groups of components that automatically generate data trees and provides insights on how to avoid common mistakes when working with data trees in Grasshopper.
Check out Exercises about Data tree structure (make sure to have metahopper plugin installed)
You have successfully joined our subscriber list. Check your inbox. Confirm email in order to get access BIM Case Studies from the biggest Norwegian projects.
Reasons to Subscribe to the BIM Corner List:
BIM CASE STUDIES
After reading this guide, you will learn:
How BIM is used on the biggest projects in Norway
What were the challenges for the design team and how were they solved
What were the challenges on the construction site and what was our approach to them
News From BIM World
Every Thursday you will get a package of news and useful links from the BIM world.
No Hype
Just real content that’s meant to make a difference in your BIM knowledge.
This site uses cookies to offer social functions, analyze traffic and conduct remarketing activities. Details can be found in the privacy policy (info button).