
How to design your data containers so that making errors is more difficult? How to keep our precious data sets useful for longer? How to maintain high-quality data throughout the life-cycle of your project? You will find answers to these and more questions in this article.
Table of Contents
Design the process
Data cleaning is not a single-time occurrence after which the data set is always correct. It is rather a recurring process and you have to keep it running on a good interval basis.
Prevention is better than cure, therefore, instead of repeatedly cleaning the data using those methods you can create a process that supports maintaining data accuracy. Even better if you could engage users in that, by giving a little nudge (in form of an example or instruction) or literally forcing them to insert correct data types. I want to share some ideas on the different possibilities. I’ll be glad if you incorporate it into your project! Or maybe you are already doing it? Let me know in the comment section under the article! 🙂
In the practical example, I will use the world’s most common software for data management – Excel. I am certain that this is still the dominant software in the AEC industry. And if you understand Excel – you will also understand other, “proper” database software even more easily.
There are about a million blogs and vlogs about Excel. Yet somehow, spreadsheets are still erroneous! Lots and lots of workers do not grasp the idea of how data should be structured. It is impossible to teach everybody how to create high-quality data. Instead, you, as data manager (or whoever is responsible for managing project data) can create an environment that enforces better data entry and reduce human errors. I hope that after this entry the spreadsheets on your project are going to be better.
Never ever do that
Let’s start with a simple don’t do list. If you want to make your spreadsheet into a structured data set, never do the following:
- Insert empty lines in the middle of your table. Otherwise, the table automatically stops right there, and your data analysis misses every occurrence after an empty line.
- Insert string values in number fields. If done so, a pivot table doesn’t work. And this is the primary feature to analyse data in Excel
- Merge rows or columns in the middle of the table. Otherwise, you cannot set filters and create a table from such data entries.
Ease data entry
This is the first and most important step. The staggering majority of data errors happen during the data entry process. Why not ease the manual work of your co-workers or suppliers? That will lead to easing the workload for you.
Create a high-quality place for data collection. Define rules for columns and rows, so that the user not only receives an error while trying to write an incorrect value but also explains to him/her what value is expected (we all hate unexplanatory error messages).
There are multiple possible approaches to that task.
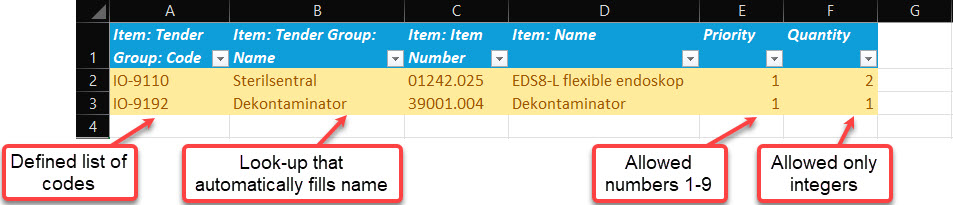
Use dropdown lists
Dropdowns are enumerated data types. If you read this article, you already know that this data type is one of the easiest to manage. Why not use them to our advantage?
You can create any dropdown list in those few steps shown in the video above:
- Create allowed data in a separate spreadsheet (you can hide it before sending it out to users)
- Go to Data Validation
- Define input type for a specified column to be drop-down
Booleans
Those are TRUE/FALSE type fields. Remember to specify which values the user should use so that your system can read them correctly. Should it be written as TRUE/FALSE or YES/NO? Or maybe you prefer it numerical – 1/0? The last is sometimes necessary to perform further calculations.
In the video above you can also learn how to create booleans fields.
An additional hint: to perform calculations on booleans, you have to convert them from text/logicals to numbers. You can use double negative before any logical function:
=--(FUNCTION GIVING TRUE/FALSE RESULT)
Automated data entry
Anything that can be automated, should be. Auto-filling on typing exists already in Excel. What more can you automate and how to do this?
Functions. Try to use most out of functions and least copying and inserting values. It automates and makes work with data much faster and secures the high-quality of the data input. In many cases, thanks to them, a user has to fill in only one cell, and the others are automatically calculated.
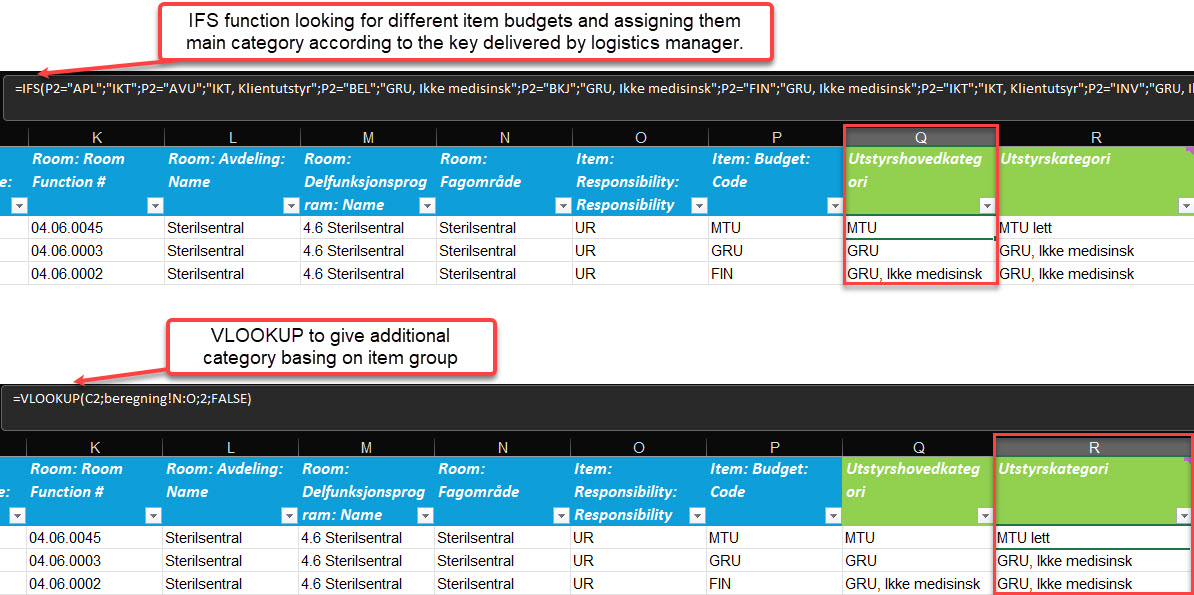
Standardise data entry methods
Having standards and defined processes is generally always a good practice. Standardising the data entry method is more important the more different tables you own and want to combine together for data analysis.
Just think of an easy example: in one table you have YES/NO, in the other TRUE/FALSE, in the third Y/N, etc. You have to cleanse and transform the data to the common standard.
The solution here might be two-fold:
- Using drop-down lists (described above)
- Filling a couple of examples of data in the table and providing a read-me on the first page/sheet
Prevent errors
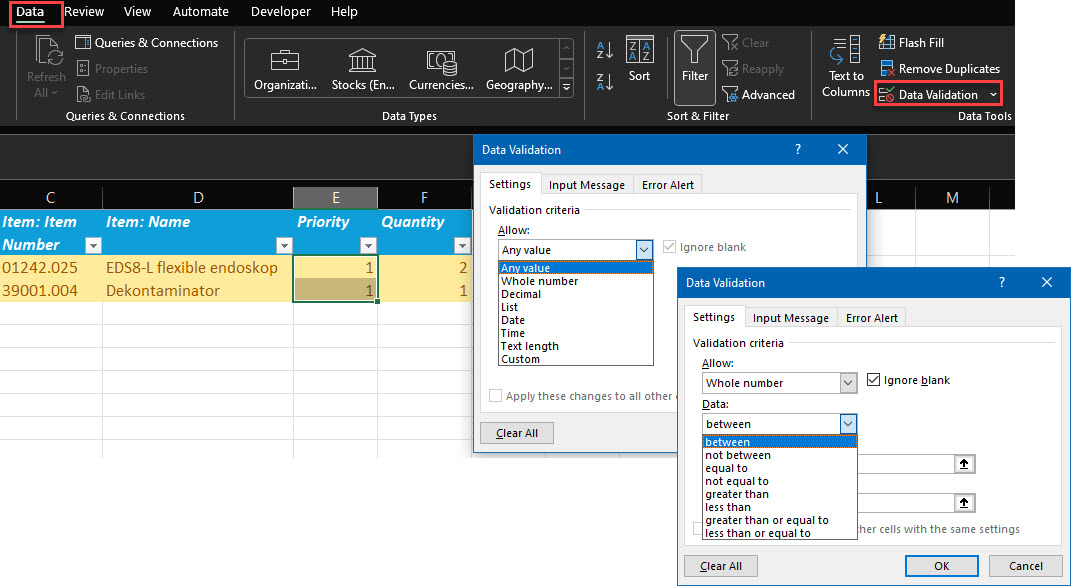
Limit string values
Refraining the possibility to enter a string value where other values are required greatly diminishes errors in the database. With just this setting you will reduce all weird data entries such as: ???, ?, 1? 1-2, maybe 3 and so on. In this article I have already referred to it and given reasons on why this is important. I encourage you to read this in the first place.
In this video you can learn how to create a data type control in Excel:
- Choose a column to allow only numeric values
- Go to Data – Data Validation – settings
- Allow: custom, Formula: “=ISNUMBER(A2)”
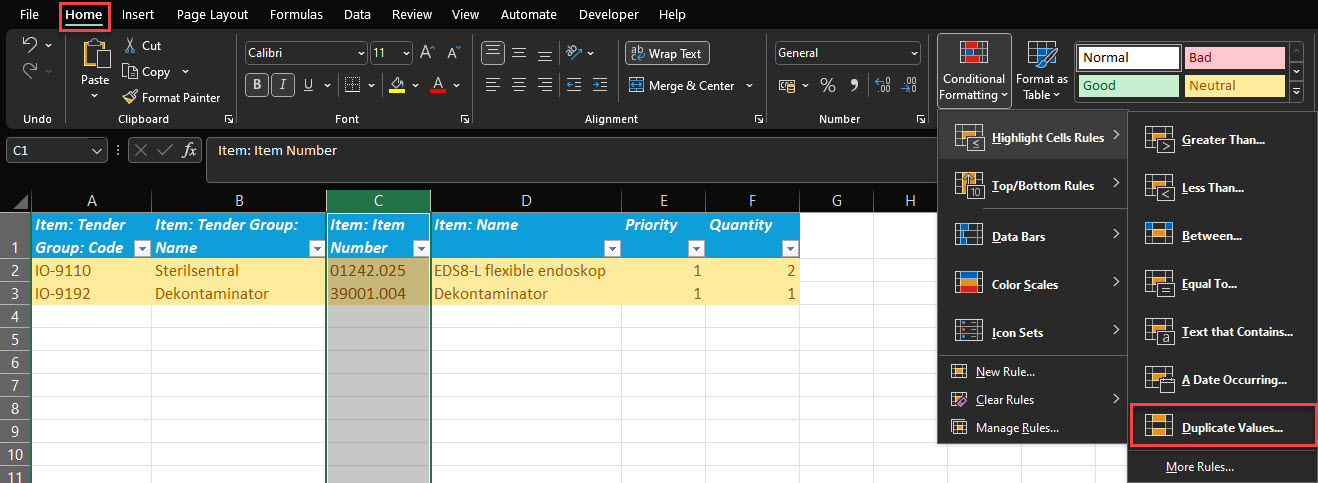
Prevent duplicates
In Excel, you can either forbid creating duplicates by using Data Validation or VBA coding (here is how), or you can create a rule (or custom formatting) that highlights duplicated values. In this way, each user will be notified in the event of duplicated value that has to be unique.
Regulate data accessibility
This is another important and often neglected (or improperly managed) stage. A database is not for everybody to edit. Especially not entirely. I have thousands of examples when one user made changes that in the end were incorrect and led to costly project changes in the later phase. Errors can derive from many sources:
- Simple mistakes (editing the wrong field or misclick)
- Insufficient knowledge (“I think this should be correct…”)
- Lack of discipline (“Yeah, I know changes are not allowed, but I think this is critical here…”)
- Unawareness of the consequences (“I have only changed one piece of equipment, it’s not much!”)
And so on, and so forth. Either way, in the end, the project has to pay for the wrong data.
This is the reason why I reckon regulating data accessibility is such an important measurement to undertake and maintain throughout the project. This means both giving access to new people only after training and removing access to those who have finished their job in the database.
It is difficult to provide you with any example of how to perform it in practice since every software is different. In Excel, you can have only read/write/comment access. Though you can limit them in time. Maybe it is worth considering?
Review and clean data
Even though you set requirements for the data types. Even though you have automated data entry wherever feasible. Even after setting up rules and conditions to prevent duplicates and after restricting access only to relevant people.
You will still get errors in your data set.
There is nothing you can do about it – errors will come. To reduce their impact on the project you should do regular checks and maintain high-quality data (you have to define what it exactly means. Yet allow it to be below 100% accurate!). You can read how to perform data quality checks here.
Periodicity of such a review is individual for every data set. It depends on how big it is (bigger sets tend to get more errors), how many people have edit rights (the more people, the more errors), how often the new data is entered (more often, more errors) and how difficult and how time-consuming is doing such an audit (the more time, the less often).
Summary
The article presented some basic measurements to maintain project data on a high level. Of course, the list is not comprehensive. Especially when sophisticated, data management software come into place. I tried to draw your attention to the creation of better spreadsheets and maintaining high-quality data level in AEC projects. I reckon this is a good start.
What do you think about the presented measurements? Do you have any additional on your project? Let me know! Also, if you know a person that would learn something new from this article – send it to him/her straight away!









1 In any document, you will find at least 3 errors,
2 Re-read at least 3 times.
🙂
Very much true to any document that is possible to check within a reasonable amount of time. Though re-reading a database containing tens of thousands rows is rather a daunting task. That’s why it is so important to get it right straight away while entering the data.