
What do you hear, most frequently along with the term BIM?
I mostly hear that BIM design generates savings, eliminates collisions and improves the design process.
At the same time, what are the challenges for designers working with BIM technology?
I hear from them that projects are getting bigger and bigger, more and more complicated, and there is less and less time to design.
Both of the above statements are correct. BIM improves the design process. However, high requirements and complexity make the design process often overwhelmed with information and disorder.
In this series, I will focus on the letter “I” in the BIM abbreviation. It seems logical that since the projects are growing, there is also an increasing amount of information. Consequently, as there is not enough time to design, there is also not enough time to make changes and revisions. In the upcoming posts, I present an approach that can save time and nerves, especially if it is applied at an early stage of the project.
It is an approach to design where data plays a major role in the project development process. Successfully applied on large and complex projects such as industrial facilities, airports, transport hubs, etc. I don’t know how this approach is implemented on infrastructure projects, but I believe it is possible after adapting certain elements.
Who is this series for, and what will you learn?
- For investors - it will help you understand how to present your requirements to facilitate the designer's workflow and minimize possible mistakes. You will see how to estimate costs without a BIM model. You will also see how to control the extent to which the project corresponds to the initial assumptions and check the project progress during the project.
- For planners - you will learn how to plan your work without even putting a line in the model, and how to create a valuable database of project information.
- For architects and industry designers - you will save time on “pasting” information from a PDF to a model by changing your approach to design. You will also find out what the design process with a database as an information center looks like.
- For BIM coordinators - you will learn a lot about configuring attributes in graphics programs and how to make databases “speak” to designer models.
Similarly to our whole blog, in this series I will focus on practical issues – I am going to present databases and workflows on projects relating to the above mentioned issues.
There are many different programs on the market to maintain the database. In the following examples, I will refer to the dRofus software, as I know it from the inside out. Graphic designs will be done in ArchiCAD, Revit, or IFC files.
I would like to emphasise that I am writing this series mainly for you, hence if there is any particularly interesting topic, please comment/e-mail me. Thanks to your feedback, I will devote more time to discuss the topic and explain it even more precisely.
List of articles
- What is Model Driven Design and Data Driven Design (this post).
- How to present information in a database? A discussion of the database on the example of the project.
- How to manage information on projects? Arrangement and implementation of the information contained in the model.
- How to present the project in a way that everyone knows what I want? Data Driven Design for the Investor.
- How to plan a project without drawing a single line? Data Driven Design for the Planner.
- How to ensure that design changes won't be an overkill for my team? Data Driven Design for Architect and Industry Designer.
- How to combine the graphic with the non-graphic? Data Driven Design for BIM Coordinator.
- How to estimate costs without using a model?
- What to do next with all the information I have in the database? Data Driven Design for Facilitiy Management.
- Other elements that create Data Driven Design
Article 1: What are Model Driven Design and Data Driven Design
In the following post, I focus on the fundamentals that allow you to understand the broader context of the series. I describe and compare two design processes – the “traditional” approach to BIM modeling and data-based design.
Table of contents
Current designing process
BIM has already settled in the industry and no one who has tried model-based design ever thought of going back to 2D. At the same time, in the information management process nothing has changed compared to AutoCAD. I will discuss below the current process with an emphasis on collecting design information and introduce the places where the lack of appropriate processes is the most challenging.
In its current form, the BIM design process begins with close cooperation of the investor and the design team. They work together to obtain and collect information as well as requirements regarding the project, which we store in the Common Data Environment (Everything You Should Know About Basics of BIM information chapter). Such data is normally available in many different forms:
- Model sketches
- Excel with a list of rooms and areas
- PDFs with requirements and technical descriptions for each industry
In the subsequent phase, a 3D model (often several 3D models) is designed according to the requirements specified in the previous phase of the project, using BIM authoring tools (Revit, Archicad, Tekla, etc.) It starts with entering basic and generic information on the elements. Consequently, as the project progresses, and depending on whether the project requirements are at a high level, designers further enhance the models.
This is followed by validation of everything that has been designed concerning:
- Legal requirements
- Investor requirements
- Other industries (this is the role of BIM Coordinator)
In this phase the uncertainty of the correct information source is the most vulnerable. Is it the one in the model or is it in the documents on the CDE? This is the quality control that makes many investors throw up their hands and admit that they have no good workflow.
In case of discrepancies between the requirements and the design, it is necessary to redesign the individual elements and their attributes.
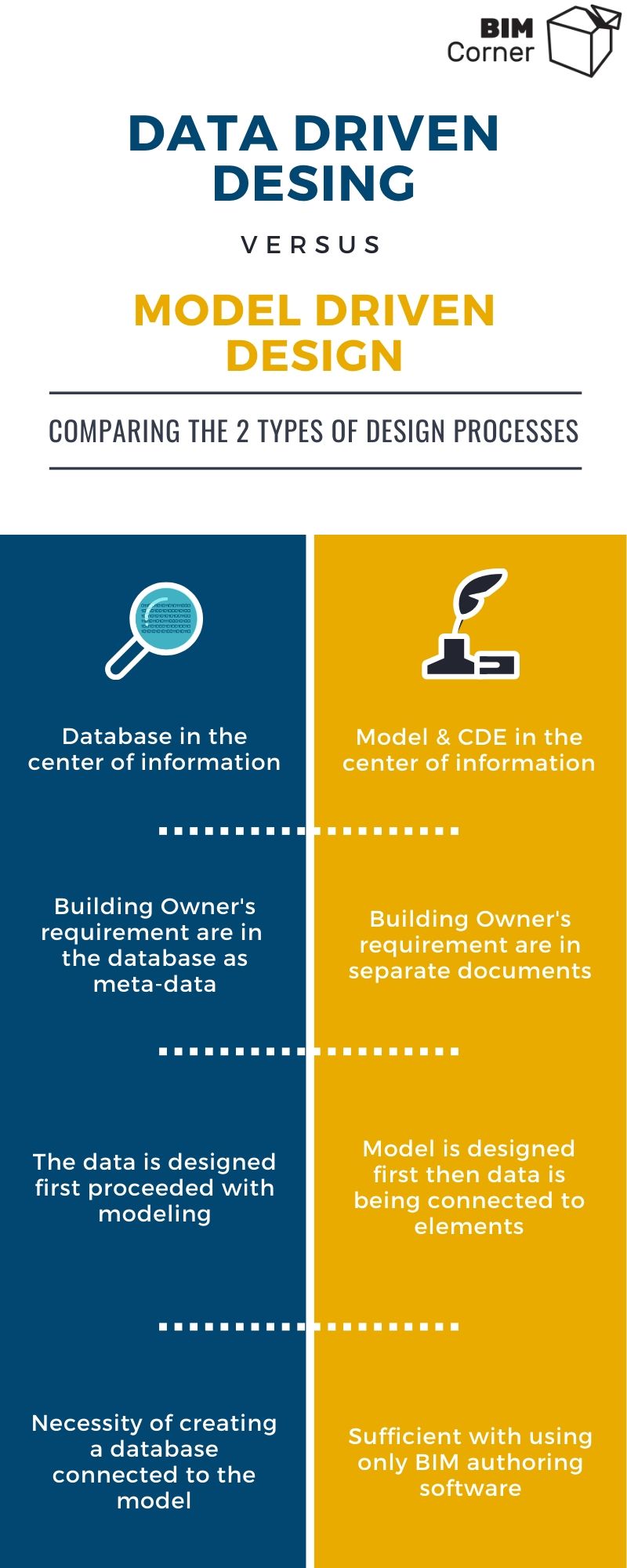
That design method is called Model Driven Design – the central place of project information is the model(s) and CDE, where the documents are located.
The process may be presented in the diagram below:

Pros and cons of Model Driven Design
The Model Driven Design method offers many obvious pros:
- The designers work with one tool they are familiar with. It makes the design process runs smoothly.
- A high-quality, multidisciplinary 3D model is created.
- The information is assigned to the elements in the model, making it possible to access data at any time throughout the development (also using free IFC-reading tools).
- All authorized members of the design process have access to the design information and requirements on the CDE.
- You can read about other pros in our article: Why should I use BIM Technology.
Unfortunately, it is not perfect and has some significant cons, such as:
- Files size – if we enter all the project information into the model, the file size increases and the flow and transparency of the model decreases.
- Managing a collection of data – it requires a lot of time to find and generate the desired schedules, tables or sorting data. Managing data within the modeling programs is thus coarse.
- Double source of truth – in case of design requirements in files disconnected from the model, there is a danger of losing control over the true and correct source of information.
A simple and practical example – rooms in a building where we need to specify the number of power sockets:- During the coordination meeting, it was agreed to have 10 sockets each in all meeting rooms.
- The original requirements included 5 sockets.
- 10 sockets were modelled according to the note from the coordination meeting.
- However, the investor does not update their requirements document (it happens, for example, due to the lack of time or by mistake).
- After a while, the case returns and a question arises – why do we have 10 sockets when the requirements clearly state 5?
- Validation – comparing the model with the requirements developed in separate documents is both manual and time-consuming. This takes up the lion’s share of the workload, and often done superficially and inaccurately due to a lack of time or resources.
- Redesign – having validated the project it may be necessary to redesign the model, e.g. the wall or ventilation duct. This involves changing the geometry of the room or other surrounding elements. As a result, a single change may require a large part of the building to be redesigned.
- Checking the progress/advance of the project – graphically, BIM projects do not vary much after the sketch phase, thus it is difficult to recognise the progress of the project at first sight.
To eliminate these cons, many designers and investors began to consider changing the design process to one where the information collected in one place will constitute the entire knowledge repository and will be capable of updating the model on an ongoing basis.
Data Driven Design
The starting point for the development of the process was to eliminate the cons of the previous point while maintaining the pros of the BIM design process. The solution was to connect information from the early project development stage with the developed model.
The assumption of the data-driven design process is a central database, which gathers as many requirements and data as possible and then synchronise and map the pieces of information with the model.
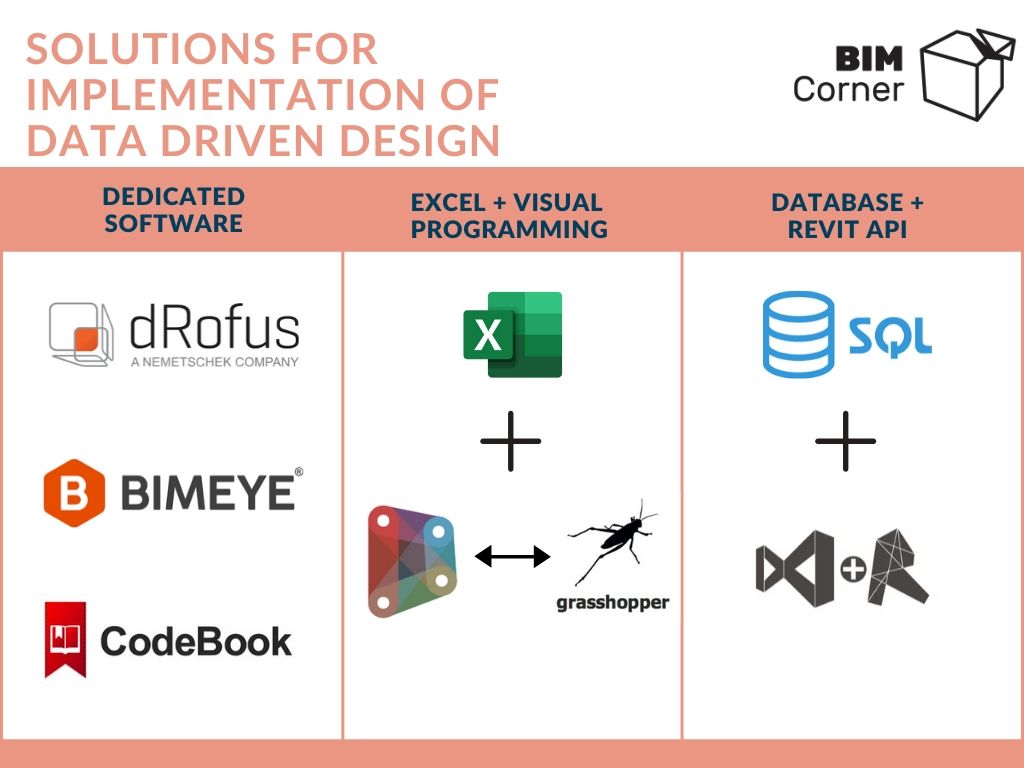
It is possible to solve this issue by:
- Dedicated software: dRofus, BIMEye, Code Book, Building One and several other tools.
- Excel connected to the model. It is neither a nice nor simple solution, but certainly the cheapest – a well-structured Excel, which then automatically transfers the data to the appropriate attributes using an external plug-in or script in Dynamo or Grasshopper. An article presenting the fundamentals of the Dynamo-Excel combination
- A theoretical option to connect an SQL database to graphic programs. However, it requires knowledge of SQL and the API of modeling programs.
In the early design phase, investor, planner and architect cooperate by using a common database. Pieces of information and requirements are written into the database instead of documents and Excel, dividing boards into planned functions, departments and rooms.
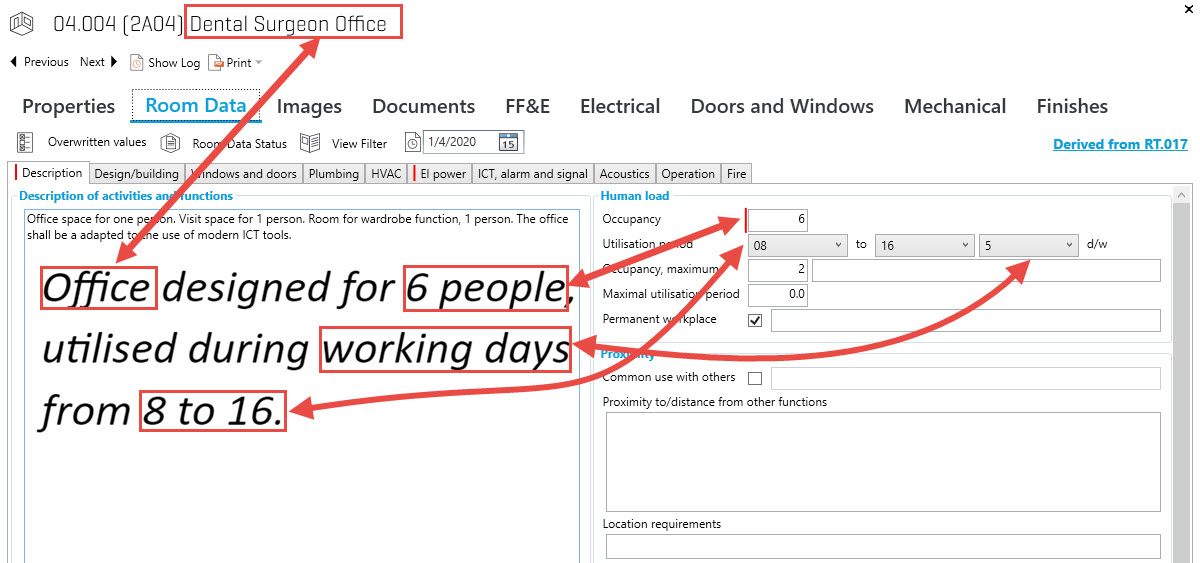
For the process to be applicable, an appropriate form of data is required – these must be metadata, i.e. a set of structured information that facilitates finding, identifying, and managing them. Example:
- Instead of: Office space designed for 6 people, available on working days from 8 am to 4 pm.
- We create boards with the above data in the form of metadata:
In the following phase, we enrich the project with specific data, according to the investor’s requirements. These may be, for example, significant objects (hospital equipment), expensive building elements or installations in the building. The introduction of such information enables a simple and quick estimation of the total budget and the total planned area divided into sections.
Such information then serves as a basis for validation. Since the structure of the database reflects the structure of the construction project (more about this in the post showing database structure), it is possible to coordinate the project already in the initial phase. Designers can introduce modifications and adjust the project without the need for graphical redesign. We save one step – introducing design modifications at a later stage based on 3D objects.
After validation and adjustments, we start designing objects. Designers can determine appropriate data mappings (value assignment between programs – as in the graphics below) as well as the way of synchronization between the external database and the model. It enables more efficient geometry modeling using information placed in tables (attributes are already defined). And hence by running a script or synchronization with the software, they are filled with information from the database.
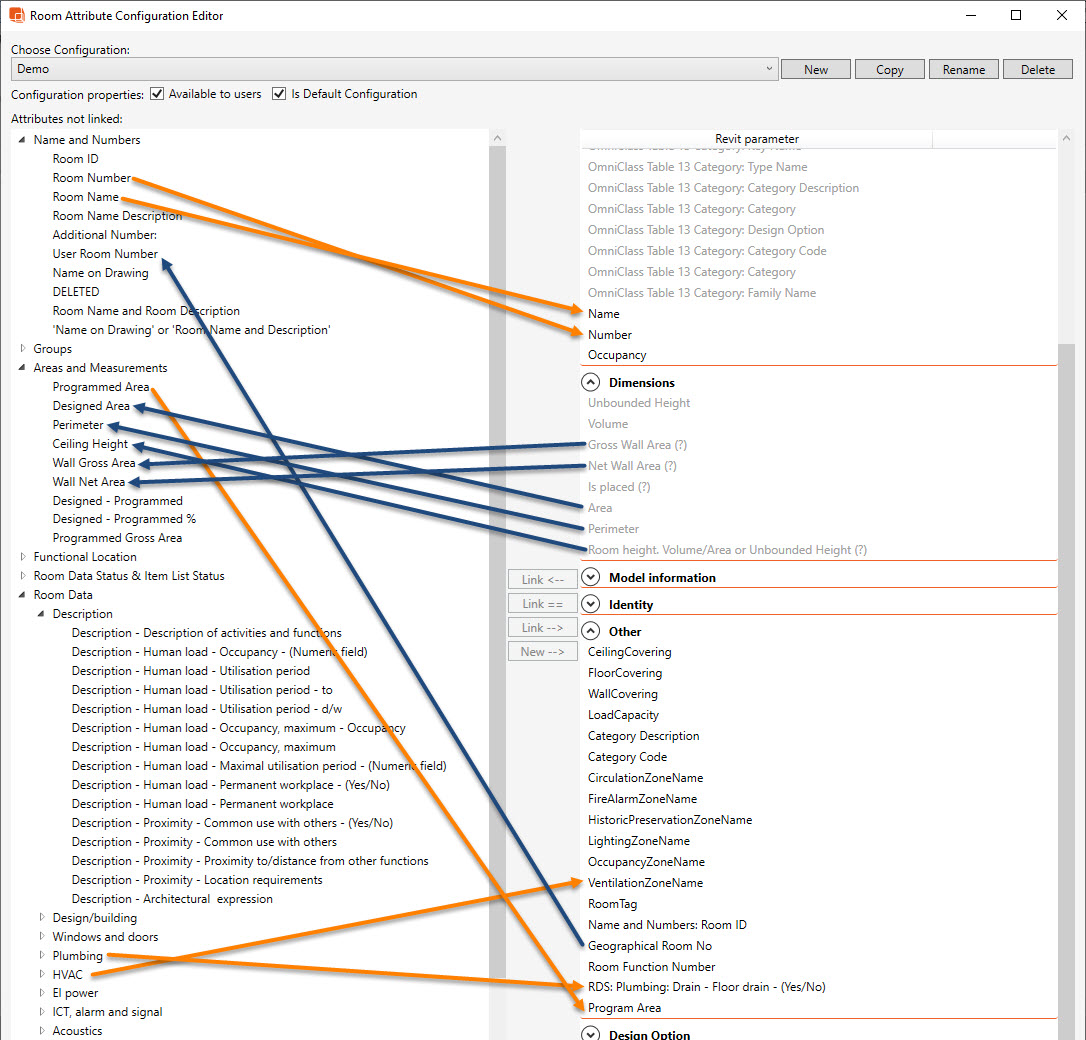
How does all that help? You do not have to enter all attributes manually into the model, thus speeding up modeling, but also ensuring the correctness of project data – after all, they reflect what was agreed with the investor.
Unfortunately, we are not able to completely eliminate object-oriented redesigning – after all, modifications appear at different phases, and sometimes very late. At the same time, thanks to having a single source of information that cooperates with the models, we can put them in easily.
Below we present a sketch of the process where data is the motor of design, and determine the model.

Pros and cons of Data Driven Design
The pros of the data-based design process represent a reaction to the cons of model-driven design:
- Files size – thanks to the fact that we do not need to keep all attributes in objects, files are much smaller.
- Information management – database workflow opportunities are the same as with Excel. Filtering, searching, sorting rows and columns is simple and fast.
- A single source of truth – all information starts with an entry in the database which determines the turth. And thanks to the background synchronization with modeling programs, we may easily transfer the data between those two sources.
- Validation – having all the investor’s requirements, designed data and connected model in one place, we can efficiently perform requirement vs. design control.
- Redesign – due to the possibility to perform control at an early stage of design in the database itself, or only in attributes, introducing modifications take less time. Of course, the relationship between cost of modifications and progress of the project does not alter – the later the modification is made, the more expensive and more difficult it is to implement.
- We can check the progress of the whole project through an easy insight into the progress of the data.
Unfortunately, Data Driven Design does not solve all the obstacles faced by participants of large projects:
- The design process differs from that known by designers and investors. Without being open to changes and the will to learn a new workflow and mindset, the data-based design will only be another tool and burden for all parties.
- The need to rewrite the investor’s requirements from descriptive documents to metadata – currently, documents and Excel tables continue to prevail among investors. Introducing and structuring the information requires time and is subject to the risk of error.
- Starting with the design process for the first time, we must be prepared to adapt standard databases to our requirements and create a strategy as well as modify the information flow if necessary.
- Additional costs for the project – it is not a solution available from the Revit or another tool. If we prefer a dedicated solution, there is the cost of a license or purchase of the appropriate plug-in. To lower the entry barrier, you can stay with Excel and have (or create yourself) a script for Dynamo or Grasshopper.
Summary
In the first post starting Data Driven Design series, we introduced two different approaches to design. You have already discovered the pros and cons. Hence, if you are interested in Data Driven Design methodology, I invite you to the next posts, where I will discuss in detail the following issues: how should the database and the information management strategy on the project look like. I will also introduce specific project cases for various participants of the investment project.
Let me know what you think of such an approach to design in the comment below or send a message at [email protected]. We always reply and are open to discussion!








I’m looking for the article: What is the structure of the database? A discussion of the database on the example of the project.
I can not find.
Here you have it! http://bimcorner.com/how-to-present-building-information-in-a-database/
“Starting with the design process for the first time, we must be prepared to adapt standard databases to our requirements and create a strategy as well as modify the information flow if necessary”
I don´t really understand what this means, do you mean adapting the software-standart databases(dRofus)?
Yes, that is what it mean – starting a new project database, requires some setup and adjustments to our needs and requirement. This can be especially cumbersome when working with this solution for the first time and not knowing what do you really want.
Interesting comparison. I am familiarized with MDD but the DDD aproach looks really good, but I thing also requires some extra tools and knowledge regarding metadata management. In your opinion, is the BIM Coordinator who should “traduce” the “Pieces ofinformation and requirements” into metadata? or wich figure involved into the process should do it? Thanks in advance.
Best regards
Hey Alvaro,
Thanks for the comment!
Who should transfer the data depends mostly on where in the project are you. If this is an early phase, then Project Planner or Building Owner should do that (specify Project Requirements directly into a database, not in PDF). If this is during the design, I would rather point to Architects and Discipline Designers who could transfer requirements from the Building Owner into dRofus database. And during the construction, it would be the Contractor who would do that.
The position of the person who would do that doesn’t matter really. The most important is to have it done 🙂