
Yet again, before I jump into practical aspects of PowerBI for managing BIM data I have to introduce some new concepts that I omitted in the previous entries. These relate to a database and its features.
Why databases? Power Query (the engine that allows PowerBI to manage multiple data sources) is simply speaking nothing else than a tool to join different data sources into databases and afterwards manage them in a form similar to using SQL programming language (those who know SQL – don’t hang me, this is a simplification). That is why, I thought it is necessary to give you some basic introduction to principles that rule the database world.
Table of Contents
The following article is included in the Data Management in BIM series. In case it’s the first post you came across, I encourage you to read the introduction "What is data? Introduction to Data Management in BIM". I describe there the basic concepts and at the bottom you will find table of content. All that to make sure you can get the most out of the series. Have a good read.
Why databases in BIM?
First and foremost – why has PowerBI become so popular in the BIM world? Frankly speaking – because every BIM design is a huge database. Revit is a database, ArchiCAD is a database, Tekla is a database and so on. Every object stores data that can be transferred into various tables and joined together. Some of the outcomes are well-known dynamic schedules.
The problem with those databases is that they are siloed within one design. The ArchiCAD file for architectural design is one database and the Revit file for MEP design is another database. They, yet again, don’t talk to one another. You can of course create federated models from IFCs and extract data from there, but they again land into a flat Excel spreadsheet. Which has some performance limitations when we speak about tens of thousands of rows and hundreds of columns.
Power Query enables us to manage multiple tables and the PowerBI visualisation tool has the remarkable potential of creating dynamic and informative dashboards. With some skills and time for set-up, we are able to visualise all project data in a bunch of dashboards. Sounds promising? Let’s take a ride into the database world!
Database in BIM explained in a simple way
Think of a database as a large digital filing cabinet that stores and organizes information. The data, like a collection of spreadsheets, is stored in a structured manner.
This manner is rows and columns stored in a series of tables. The data can then be easily accessed, managed, modified, updated, controlled, and organized. In other words – make it useful at a later point in time.
Databases typically have a common topic or objective. Like, for instance, a database of building information for the school project we are working on. The database is usually controlled by a database management system (DBMS). Simply speaking, it is software that allows a user to reach into this cabinet and draw from its resources (manage the data in the database).
Database vs spreadsheet
In AEC, we are very much used to Excel. We understand spreadsheets and how information should be stored to be easily managed (and if you don’t, definitely check this article out!). Databases are similar, yet designed for a little bit different purposes. Both databases and spreadsheets are two essential tools for managing and organizing data, each with its unique strengths and applications.
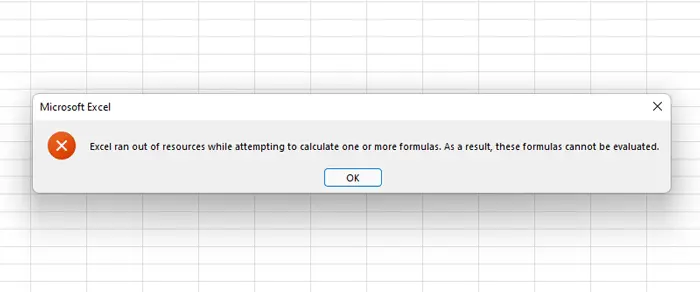
Spreadsheets offer a more flexible approach to data organization. They use a grid-like structure of cells, allowing users to input and manipulate data easily. Spreadsheets are best suited for smaller datasets and tasks that involve basic calculations, charts, and simple analysis. They are widely used for personal and small-scale data management but may become less manageable and slower as data volume increases. That is the reason we love them on construction sites – easy to set up, calculate and close. But terrible when getting bigger or more complex (Excel ran out of resources? Happens way too often to me).
Databases, on the other hand, are designed for handling large and complex datasets. They use structured tables with predefined fields to store data, allowing for efficient data retrieval and robust data integrity. Databases excel at managing relationships between different data elements, making them ideal for dealing with extensive and interconnected information. They are well-suited for tasks requiring advanced data analysis, scalability, and collaboration among multiple users.
In short, databases are the go-to choice for handling large, complex datasets and collaboration among multiple users. Spreadsheets are suitable for simpler tasks and smaller datasets, providing flexibility and ease of use. Since we want to put our whole project data into one PowerBI file, we have to go for something bigger.
Relational vs non-relational databases in BIM
The two most common types of databases are relational and non-relational. They both exist in AEC tools, but we will focus mainly on relational databases since these are exactly relations between tables that we need to understand in order to use PowerBI efficiently.
A relational database is a type of database that organizes data into structured tables, consisting of rows and columns. Each row represents a record, and each column represents an attribute or field of the data. There is a possibility for establishing relationships between multiple tables.
On the other hand, a non-relational database (also known as NoSQL database) is a database system that does not follow the traditional tabular structure. They are designed to handle unstructured or semi-structured data (such as document-based or graph-based) and offer higher scalability and better performance for certain use cases, especially those involving big data and real-time applications though they might compromise data consistency and transaction capabilities.
As a side note – you are able to connect NoSQL databases to PowerBI and retrieve data from there, but you need a third-party connector that maps and flattens the NoSQL data structure.
Useful terminology for database in BIM
We don’t need to dive into full terminology connected with databases, but I have to explain at least a bunch of them so that you will know what I am referring to afterwards. I introduced many other data-related terminology in one of my previous entries about data management.
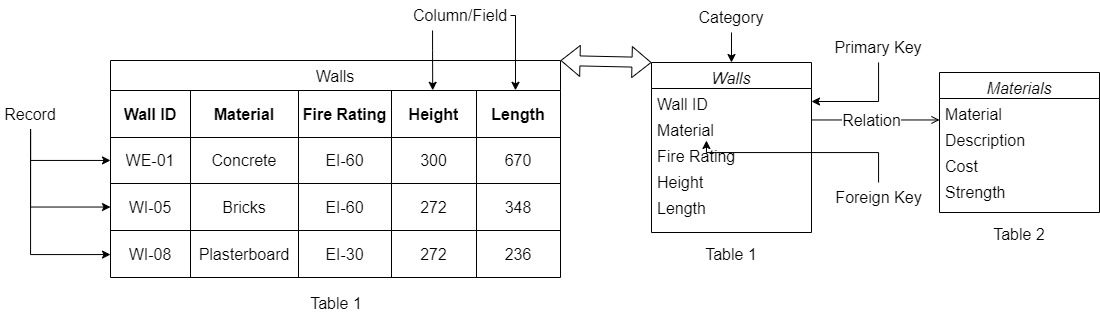
Table: In the database, a table is like a single sheet within the spreadsheet. It consists of rows and columns, where each row represents a specific entry (a record) and each column represents a different piece of information (attributes or fields).
Record: A record is like a single row in a database table. It contains all the information related to a specific item, person, or thing.
Column/Field: A column or field is like a single column in a database table. It represents a specific category of information, like names, ages, addresses, etc.
Category: Data is placed into predefined categories in those tables. Each table has columns with at least one data category,
Primary Key: A primary key is a unique identifier for each record (row) in a database table. It ensures that each row has a distinct and non-null value. In a table, you can have only one primary key. Think of it as a special ID number for each record in a table. It ensures that each record has a unique identifier, like a fingerprint for data.
Foreign Key: A foreign key is a field in a table that establishes a link or relationship between the data in two different tables. The foreign key in one table refers to the primary key in another table. It acts as a pointer to the related record in the referenced table. This helps to avoid data duplication, maintain data consistency and allows to connect and retrieve data from both tables at once.
Query: It’s like asking a specific question to the database. You can use a query to request information from the database, like “Give me all the products in the model made by X.”
Power Query: Power Query is a business intelligence tool called ETL (Extract, Transform, Load) available in Excel and PowerBI that allows you to extract data from many different sources then clean and transform it and in the end load it to the place for data analysis.
Index: An index in databases is a data structure that improves data retrieval speed. Indexing is useful for large databases, enhancing query performance. In other words, it works as an index in a book that helps you quickly find specific information. It speeds up searching and sorting data, making things more efficient.
Schema: A schema is like a blueprint or a plan that defines the structure of the database, including the tables, fields, data types, and relationships. It acts as a guide for how data should be organized and stored in the database.
Summary
The article explains key database terms which are essential for data management and visualization. I reckon understanding database concepts is crucial for efficient PowerBI use. You have to understand what creates tables and how to connect the tables together and afterwards transfer them using PowerQuery.
In the course of the next articles we are going to take a closer look into the types of relations in databases, and how Power Query works and then we will jump inside PowerBI.
Resources